The expanding use of generative-IA applications has accomplished the request for accurate, cost-effective large language models (LLMs). LLMS ‘costs vary significantly based on their size, typically measured by the number of parameters: Change to the next smaller size often results in a cost saving of 70% -90%. However, it is not always a viable opportunity for their reduced abilities compared to advanced “Frontier llms.”
While reduction in parameter size usually reduces the benefit, the evidence suggests that small LLMs, when specialized to perform a job question-question answer or text summary, can match the performance of larger, unmodified Frontier LLMs on them from This task. This opens up the possibility of balancing costs and performance by dividing complex tasks into smaller, manageable sub -tasks. Such Task Degradation Enables the use of cost-effective, less, more-specialized task or domain-adapted LLMs while providing control, increased troubleshooting and potential reduction of hallucinations.
However, this approach comes with trade -offs: Although it can lead to signal cost savings, it also increases system complexity, which potentially offset some of the original benefits. This blog post examines the balance between costs, performance and system complexity in the task’s degradation for LLMs.
As an example, we consider the case of using task coverage to generate a personal site that demonstrates potential cost savings and performance gains. However, we will also highlight the potential pitfalls of overenginering, where excessive degradation can lead to reducing returns or even undermining the intended benefits.
I. Task Degradation
Ideally, a task would be degraded to sub -tasks that are independent of each other. It allows for the creation of targeted PROMPS and contexts for each sub-task, making troubleshooting easier by isolating errors in specific sub-tasks instead of requiring analysis of a single, large, black-box process.

Sometimes, however, degradation of intolends is not possible. In these cases, fast technology or information about information may be necessary to ensure a correlation between sub -tasks. However, overenginering should be avoided as it may unnecessarily complicate workflows. It also risks sacrificing the news and contextual wealth that LLMS can give by capturing hidden conditions, with the complex context of the original task.
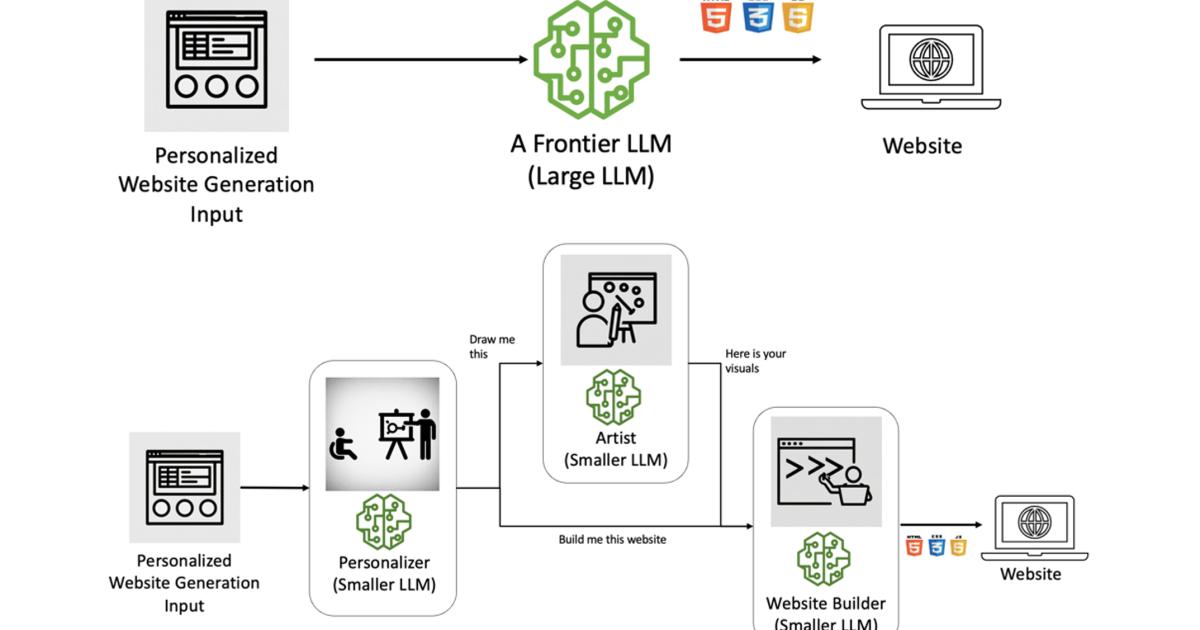
But we address these points later. First, let’s give an example where the task of personalized site generation is broken down to Agentic workflow. Tea agents In an agent work process, it may be functional agents that perform specific tasks (eg database request) or persona-based that mimic human roles in an organization (eg UX designer). In this post, focus on the staff-based approach.
Single Example: Creating a Personal Website
In our scenario, a business wants to create a site builder that generates tailor -made web experiences for individual visitors without human supervision. Generative AIS creativity and ability to work under uncertainty do it followed for this task. However, it is important to control the workflow, ensure compliance with the company’s policies, best practices and design guidelines and manage costs and performance.
This example is based on an Agentic workflow solution we published on Amazon Web Services (AWS) Machine Learning-Blog. For this solution, we shared the overall process in sub-tasks of a type of commonly assigned to human agents, such as Personalizer (UX/UI Designer/Product Manager), artist (Visual-Art Creator) and site builder (front-end developer).
The Personalizer Agent aims to provide tailor -made experiences to the site visitors by considering both their profiles and the company’s policies, offers and design methods. This is an arourage size text-to-text LLM with some reasoning skills. The agent also incorporated the generation of retrieval (RAG) to exploit Veted “Company Research”.
Here’s a trial prompt for personalization:
You are an AI UI/UX designer who is tasked with creating a visually appealing site. Remember the pain points of the industry [specify relevant pain points — RAG retrieved] To ensure a tailor -made experience for your customer [provide customer profile — JSON to natural language]. In your responsibility, give two sections: a site description for front-end developers and visual elements for the artists to follow. You must follow the design guidelines [include relevant design guidelines].

The role of the artist’s agent is to reflect the description of visual elements in a well -defined image where a background image or an icon. Asking for text-to-picture is more straightforward, starting with “Create one [extracted from personalizer response]. “
The final agent is the front-end development, whose only responsibility is to create the front-end site’s artifacts. Here you can include your design systems, code pieces or other reporting. In our simple box we used this prompt:
You are an experienced front-end web developer who is tasked with creating an available, [specify the website’s purpose] Website while complying with the specified guidelines [include relevant guidelines]. Read carefully ‘The Site Description’ carefully [response from personalizer] Provided by UI/UX designer AI and generates the required HTML, CSS and JavaScript code to build the described site. Make sure that [include specific requirements].
Here you can continue the procedure of a quality assurance (QA) or perform Agent one last passport to see if there is a discussion.
II. The great trade -off and the trap of overengineering
Task Degradation typically introduces additional components (new LLMs, orchestrators), increases the complexity and adds overhead. While smaller LLMs may provide faster performance, the increased complexity can lead to higher latency. Thus, task -provoking must be evaluated within the wider context.
Let’s resume the task complexity as O (n)where n is the size of the assignment. With a single LLM, the complexity grows linearly with task size. On the other hand in parallel task degradation with k Subtasks and k Smaller language models, the initial degradation has a constant complexity – O (1). Each of k Language models treat its assigned sub -task independently with a complexity of O (n/k)Assuming a smooth distribution.
After treatment the results are from k Language models need coordination and integration. This step complexity is O (kM)Where full pairs coordination gives M = 2, targets in reality, 1 M ≤ 2.
Therefore, the total complexity of using multiple language models with task coverage can be expressed as
ISLANDK-llms = O (1) + K (o (n/k)) + O (kM) → O (n) + O (kM)
While the single -language method has a complexity on O (n)The Multiple-Langa-Model approaches introduce an additional termin, O (kM)Due to coordination and integration cost with 1 < M ≤ 2.
Too small k Values and pairs connection, O (kM) Overhead is insignificant compared to O (n)Which indicates the potential advantage of the multiple-language model approach. However k and M Growing, tea O (kM) Overhead becomes meaningful, potentially reduced the benefits of tasking the task. The optimal approach depends on the task, the available resources and the exchange between performance gains and coordination costs. Improving technologies will reduce MThe complexity lowers by using multiple LLMs.
A mental model for costs and complexity
A useful mental model to decide that there is degradation of the degradation of the task is to consider the estimated total cost of ownership (TCO) for your application. As your user base grows, infrastructure costs become dominant, and optimization methods such as breakdown of task can reduce TCO despite costs in advance and science costs. For smaller applications, a simpler approach, such as choosing a large model, can be more appropriate and cost -effective.
Overengineering versus news and simplicity
Task Degradation and creation of agent workflows unless LLMs can come at the expense of the news and creativity that larger, more powerful models often show. By “manually” dividing tasks into sub -tasks and relying on specialized models, the overall system may not capture the serendipite connections and new insights that can come from a more holistic approval. In addition, the process of creating intricate requests to fit specific sub -tasks can result in overly complex and intricate prompts, which can contribute to reduced accuracy and increased hallucinations.
Task Degradation using more, smaller, fine-tuned LLMs offers a promising approach to improving cost-effective to complex A applications, potentially providing significant infrastructure cost savings compared to using a single, large, limit model. However, care must be taken to avoid overgaining, as excessive degradation can be increased complexity and coordination costs to the point diminishing returns. Turning the right balance between costs, performance, simplicity and preserving AI creativity will be the key to locking the full potential of this promising approach.