
A way for online shoppers that practically test products is a sought -after technology that can create a more immersive shopping experience. Examples include realistic draping of clothing in a picture of the shopper or insertion of pieces of funnitue in pictures of shoppers living space.
In the clothing category this problem is traditionally known as Virtual sample; We call it more general problem targeting any category of product in any personal surrounding Virtual try-all Problem.
In a paper we have recently sent in Arxiv, we presented a solution to the virtual-try-all-all problem called diffuse-to-choose (DTC). Diffuse-to-Choose is a new generative-IA model that allows users to seamlessly insert any product on any rent in any stage.
The customer starts with a personal stage image and a product and pulls a mask in the stage to tell the model where you have to insert the object. The model then integrates the subject into the stage with realistic angles, lighting, shadows and so on. If necessary, the model gives new perspectives on the subject and it retains the fine -grained visual identity details of the product.
Diffuse-to-choose
New “Virtual Try -All” method works with any product, in any personal setting, and allows you to change precise control of image regions.
The diffuse-to-choice model has a number of properties that separate it from existing work with related problem. First, it is the first model that adds to the virtual-try-all problem, as opposed to the virtual-try-on problem: It is a single model that works across a wide rage of product categories. Secondly, it does not require 3D models or more views of the product, only a single 2-D reference image. It also does not require disinfected, white background or professional-studio quality images: it works with “in the wild” images, such as regular mobile phone images. It’s fine, it’s fast, efficient cost and scalable, which generates an image for approx. 6.4 seconds on single AWS G5.xlange -Back (NVIDIA A10G with 24 GB GP GPU memory).
Under the hood, diffuse-to-choose is a paint of latent division model with architectural improvement that allows it to preserve the product’s fine-grained visual details. A diffusion model is one that is included who is trained to denise that is introduced noisy input and a latent-diffusion model is one where denoising occurs in the model’s representation (latent) space. Paint is a technique where part of an image is masked and the latent diffusion paint model is trained to fill (“Maint”) the masked region with a realistic reconstruction, sometimes guide with a text prompt or image reference.
Like most paint models, DTC uses an Encoder-Decoder model known as a U-network to perform the diffusion modeling. The codes of the U-net consists of an intricate neural network that gives the input image in small blocks of pixels and apps a battery with filters for each block looking for specific image features. Each layer of the codes pulls down the solution of the image representation; The decoder pulls up the solution again. .
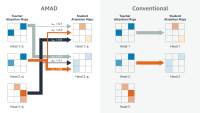
Our hand innovation is to introduce a secondary U-net into the diffusion process. Input to this codes is a rough COP-Pass collage, where the product image, which has changed size to match the scope of the background scene, is inserted into the mask created by the customer. It is a very raw approximation of the desired output, but the idea is that the coding will preserve fine -grained details of the product image that the final image registration will incorporate.
We call the secondary cod’s output a “tip signal”. Both IT and output from the primary U-NET’s Encoder Pass to a functional linear modulation (film) module that adjusts the features of the two codes. Then the coding passes to the U-Net decoder.
We trained diffuse-to-choose on AWS P4D.24xlage deposits (with NVIDIA A100 40GB GPUs) with a data set with a few million peers of public images. In the experiment, we compared its performance on the virtual-try-all task with those from oven different versions of a traditional image device paint model, and we compared it to the advanced model on the more specialized virtual-to-one task.

In addition to human-based qualitative evaluation of equality and semantic blend, we used two quantitative measurements to assess performance: Clip (contrasting language-pre-rule) Score and Fréchet Inception Distance (FID) that measure the realism and diversity of generated images. On the virtual-try-all task, DTC surpassed all the oven image-conquested paint of base lines on both measurements, with a 9% margin over the best priesting baseline.
On the virtual-try-on task, DTC was comparable to the baseline-lit higher in clip score (90.14 against 90.11), but also slightly higher in FID, where lower is better (5.39 vs. 5.28). But given DTC’s generality, performing comparable to a specialist -public model on its specialized task is a significant performance. Fixly, we demonstrate that DTC’s results are comparable in quality with those who are order-of-makerude, more expensive methods based on few shot fine tuning on each product, like our previous Dreampaint method.