
The calculation notebook is an interactive, web-based programming interface based on the concept of a LAB notebook. Users can describe the calculations that perform – including charts – and embed code in the laptop, and the laptop performs the code and integrates the results of the notebook layout.
Jupyter Notebook is the most popular implementation of computer books, and it has become the chosen tool for data scientists. In September 2018, there were more than 2.5 million public Jupyter notes on GitHub, and this number has grown rapidly.
However, the use of Jupyter Notebook poses several challenges related to maintenance code and machine learning of best practices. We recently exceeded 2,669 machine learning (ML) practitioners, and 33% of them mentioned that notebooks are easily coagulated due to the mixture of code, documentation and visualization. Similarly, 23% silent bugs found difficult to detect, and 18% agreed that global variables are used incontinence. Another 15% found the reproduction of notebooks to be tough and 6% had difficult to detect and remedy safety vulnerability in laptops.
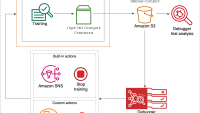
We are pleased to share our recent launch of the Amazon Codeguru extension to Jupyterlab and Sagemaker Studio. The extension integrates seamlessly with Jupyterlab and Sagemaker Studio, and with a single button click it can give users feedback and suggestions for improving their code quality and security. To learn more about how to install and use this extension, check out this user manual.
Static analysis
Traditional software development environments often use static analysis tools to identify and prevent errors and enforce coding standards, but Jupyter notes are currently missing such tools. We at the Amazon Codeguru team, which has developed a portfolio of code analysis tools for Amazon Web Services customers, so that a great opportunity to customize our existing tools for notebooks and build solutions that best fit this new problem.
We presented our original efforts in a paper published on the 25th International Symposium on formal methods in March 2023. In the following, we give two examples of how our new technologies can help experts in machine learning to be more productive.
Execution order
Code is embedded in calculation notebooks in Code cellswhich can be performed in any order and edited on the go; That is, cells can be added, deleted or changed after other cells are performed.
Although this flexibility is great for exploring data, it increases the problems of reproducibility, as cells with shared variables can produce different results as they run in different orders.
Ounce a code cell is performed, it is assigned an interest nomber in the square bracket on its side. This number is called the execution count and it indicates the cell’s position in the execution order. In the example above, when code cells are performed in non -linear order, the variable, the variable Z Ends with the value 6. However, EXECT COLLECTION 2 is missing in the portable file, which can be done for several reasons: Maybe the cell was performed and deleted afterwards, or maybe one of the cells was performed twice. In any case, it would be difficult for another person to reproduce the same result.
To capture problem men caused by execution outside order in Jupyter notes, we developed a hybrid approach that dynamic information and static analysis. Our tool collects dynamic information during the performance of laptops and then converts notebook files with python code cells for new python representation that model the execution order as well as the code cells as such. Based on this model, we are able to utilize our static analysis engine for Python and design new static analysis rules to catch from in laptops.
APIs
Another common problem for notebook users is the abuse of machine learning APIs. Popular machine learning libraries such as Pytorch, Tensorflow and Keras simplify the development of AI systems to a great extent. Due to the complexity of the field, the high level of libraries, and the unclear conventions that regulate library functions, library users often abuse these APIs and inject errors in their notebooks without even knowing it.
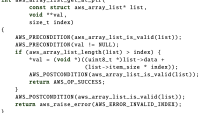
The code below shows such an abuse. Some layers of a neural network, such as apostasy, may behave differently during training and evaluation of the network. Pytorch requires explicit call to train() and Eval () To denote the start of education and evaluation respectively. The code example is designed to load a trained model from the disk and evaluate it on some test data.
However, it has the invitation to Eval ()As standard, any model is in the training phase. In this case, some layers will indirectly change the network’s architecture, which would make all prediction unstable; IE, for the same input, the predictions would be different at different times.
# noncompliant case
model.load_state_dict(torch.load("model.pth"))
predicted = model.evaluate_on(test_data)
# compliant case
model.load_state_dict(torch.load("model.pth"))
model.eval()
predicted = model.evaluate_on(test_data)
Instabilities caused by this error can have a serious influence. Even when the error exists (currently through manual code review) and firm, the model must be trained. Depending on how large the model is and how late in the development process the error is found, this can mean a waste of thousands of hours.
The best case would be to record the error directly after the developer writes the code. Static analysis can help with this. In our paper, we implemented a set of static analytical rules that automatically analyze the machine learning code in Jupyter notes and be able to detect such errors with high precise.
In experiment that involved a large set of portable files, our rules found an average of an error per Seven notebooks. This result motivates us to dive deep into the belly detection of Jupyter notes.
Our study identified the following that the Notebook users are interested in:
- Reproducibility: People often have a hard time reproducing results when moving notebooks between differentities. Notebook code cells are often performed in non -linear order which can be reproducible. About 14% of study participants only collaborate on notebooks with others when models need to be pushed into production; Reproducability is even more crucial to production books for production.
- Correctness: People introduce silent correctness bugs without knowing it when using machine learning libraries. Quiet bugs affect model outputs but do not cause program accidents, making them extremely difficult to find. In our study, 23% of participants confirmed this.
- Readability: During data exploration, notebooks can easily become cluttered and difficult to read. This inhibits maintenance as well as cooperation. In our survey, 32% of participants mentioned that readability is one of the greatest difficulties in using notebooks.
- Performance: It is time and memory-consuming to train large models. People want help to do both training and runtime execution of their code more efficiently.
- Security: In our study, 34% of participants said that security awareness among ML practitioners is low and that there is a resulting need for security scanning. Becuse NotBooks often depend on external code and data, they can be vulnerable to code injection and data processing attack (manipulation of machine learning models).
These findings pointed us to the kinds of problems that our new analytical rules should tackle. As a rule Sourcing and Specification Phase, we asked ML experts for feedback about the utility of the rules as well as examples of compatible and non -compatible cases to illustrate the rules. After developing the rules, we invited a group of ML experts to evaluate our tools in the real world. We used their feedback to improve the accident in the rules.
The newly launched Amazon Codeguru extension to Jupyterlab and Sagemaker Studio enables enforcement of cod quality and security in calculation notebooks to “change the left” or move earlier in the development process. Users can now detect safety vulnerability – such as injection errors, data leaks, weak cryptography and lack of encryption – in notebook cells along with other common problems affecting readability, reproducibility and correctness of the calculations performed by notebooks.
Recognitions: Martin Schäf, omer TRIPP