[Editor’s note: A condensed version of this blog post appeared previously in IEEE Spectrum]
“What do I need for cold weather golf?”
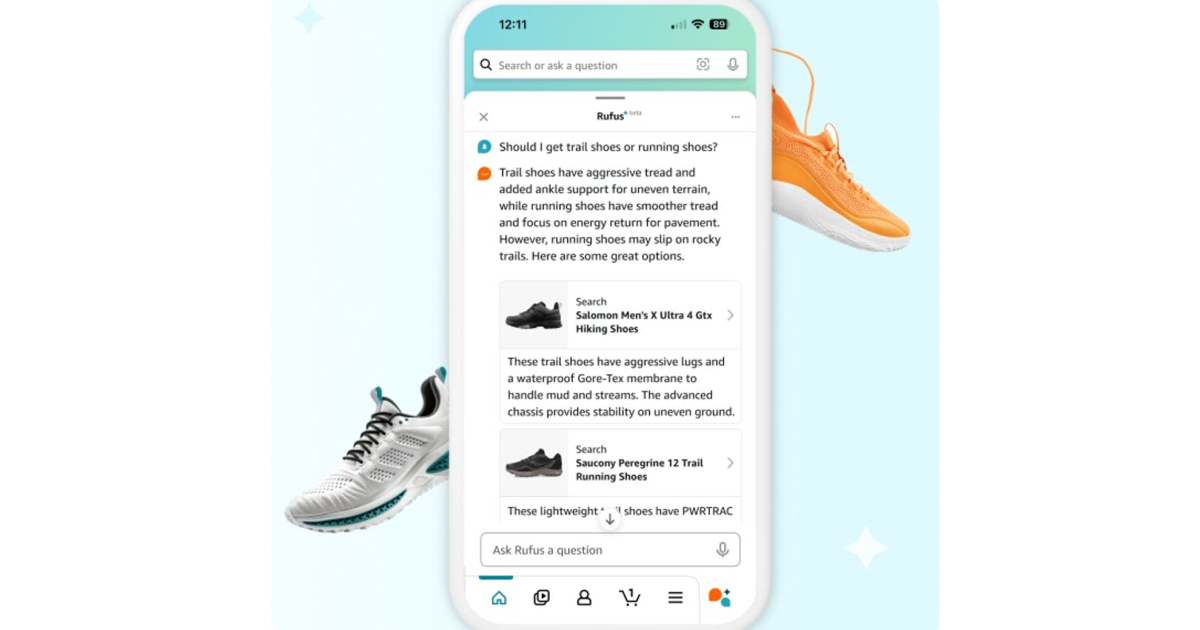
“What is the difference between trail shoes and running shoes?”
“What’s the best dinosaur toy for a five-year-old beerol?”
These are some of the open questions that customers can ask a useful sales officer in a brick and mortar shop. But what about shopping online? How do customers navigate online choices?
The answer to Amazon is Rufus, a generative-a-power-cowled shopping assistant. Rufus helps Amazon customers take more informed shopping decisions by answering a host of questions in the Amazon Shopping app, from product details and comparisons to recommendations. And that is because of progress and innovations in AI.
My team leads the scientific and technical effort behind Rufus. To build a useful conversation -shopping assistant, it was critical to use innovative technologies across several aspects of generative AI. This included building a custom large language model (LLM) specialized in shopping; Using retrieval-Augmented Generation (RAG) with a number of sources of evidence; Reinforcement of learning to improve resorts; Make progress in high press -calculation to improve the inference effective and reduce latency; And the implementation of a new streaming architecture for bitter customer experience. We chose AWS infrastructure, included the AWS-chips training and infrenenti to deliver these experiences on scale because the most advanced, safe, ravages and pricing generative-a foundations.
Building a custom llm from the bottom
Most LLMs are trained on data sets that improve their overall knowledge and capacity, and then they are adapted to a particular domain. From the beginning, our love with Rufus was to train the primary with shopping data -the entire Amazon catalog, to begin with, as well as customer reviews and information from Community Q&A posts. Our researchers build an advanced, custom LLM that incorporated this data together with public information online, carefully curating the contribution from each data source to model training. We used the AWS service Amazon EMR-A Cloud Big-Data platform to perform large-scale distributed data processing to prepare the data and the Amazon S3, the leading cloud storage solution, to store the data. Both services played a key role in creating a safe and reliable foundation for building the custom model.
Using RAG to Surface Well Sourced Answer
To answer the huge span of questions that may be asked, Rufus must be able to go beyond the training data and use information it has been before. This is where RAG comes in: Before LLM generates an answer, LLM first selects information that may be useful for answering shoppers’ questions.

But how does it know what information to choose? Rufus Pourl’s information from sources it knows to be reliable, such as customer reviews, the product catalog and the question of society and answers along with calling link stores APIs. The complexity of our RAG process is unique, both because different our data sources and the different relevance of each one, depending on the question.
Constant improvement through reinforcement learning
Each LLM and any use of generative AI is an ongoing work. In order for Rufus to become more useful over time, it is necessary to learn that reactions are useful and which can be improved. Through a process called reinforcement learning, customers can be the best source of this information. Amazon encourages customers to give Rufus feedback and let the model now if they liked or did not like answers. Over time, Rufus learns from customer feedback and improves its answers, generating answers that better help customers shop.
Make latency time and high thrushput with Amazon’s AI chips
Rufus must be able to keep wild, which is why the middle of customers at the same time without any noticeable delay. These are especially challenging Singe generative-IA applications are very computational intensive, especially on the scale of Amazon.

To minimize latency while maximizing the flow, we turned to Amazon’s Trainium and Infrentia chips, which are integrated with Core AWS services. We work with the Neuron Compiler team to implement optimizations that improve the model effective inference, and we have made these optimizations available to all AWS customers. Choosing Amazon’s homework AI chips enabled our team to move quickly, insert on scale and keep up with the customer.
With LLMs, however, flow and latency can still be compromised by standard methods for processing requests in batches. It is because it is difficult to predict how many tokens (in this case text, such as words or punctuation signs), an llm will generate as it compensates a resp. Our scientists the world with AWS to enable Rufus to use continuous Batching, a new LLM-Inference Safety Technique that makes routing decisions to new requests after each token is generated. This allows the model to start operating new requests as the first request in the batch finish, rather than ATING for all requests to complete, so shoppers get their answers faster.
Streaming Architecture
We want Rufus to give the most linking and useful answers to a given question. Sometimes it is a text in long form, but sometimes it is short form or a clickable link that helps the customer navigate the store.
Presents the answer in a way that is for the customer to interpret gifts their own technical difficulties. The information must follow a logical current. If we did not group and formatted things correctly, we could end up with a confusing responsible that is not very useful.
With an advanced streaming architecture, Rufus is able to provide a natural customer experience. End-to-end streaming on the token-for-token basis means that customers do not need to wait for a long answer to be fully generated. Instead, they get the first part of the answer while the rest is still running. RUFUS will fill the streaming response with the right data – a process called hydration – by making queries for internal systems. It is trained to generate Markup instructions that specific Howwer elements must be displayed, in addition to answering the customer’s questions, resulting in a unique useful experience for the customer.
Although Amazon has been using AI for more than 25 years to improve the customer experience, Generative AI suppresses something new and transformative – forming Amazon, its customers and those of us on science teams that get to build experiences beyond what was possible. We are pleased to speed up our pace in innovation for customers with generative AI and believe it will transform any customer experience in the coming months and years.