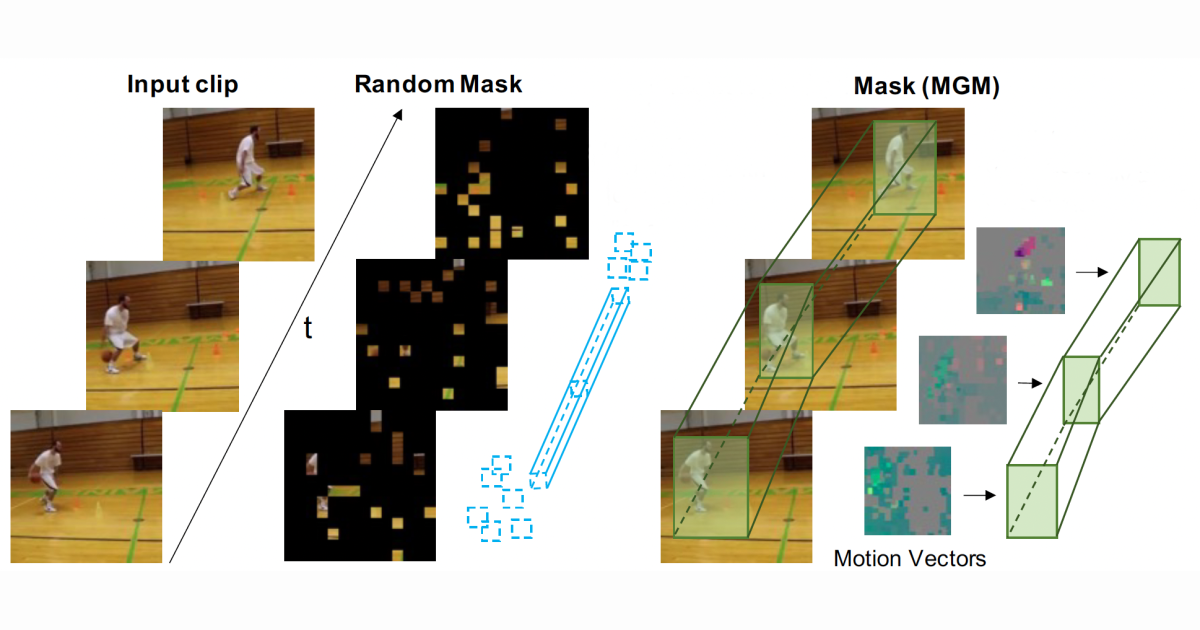
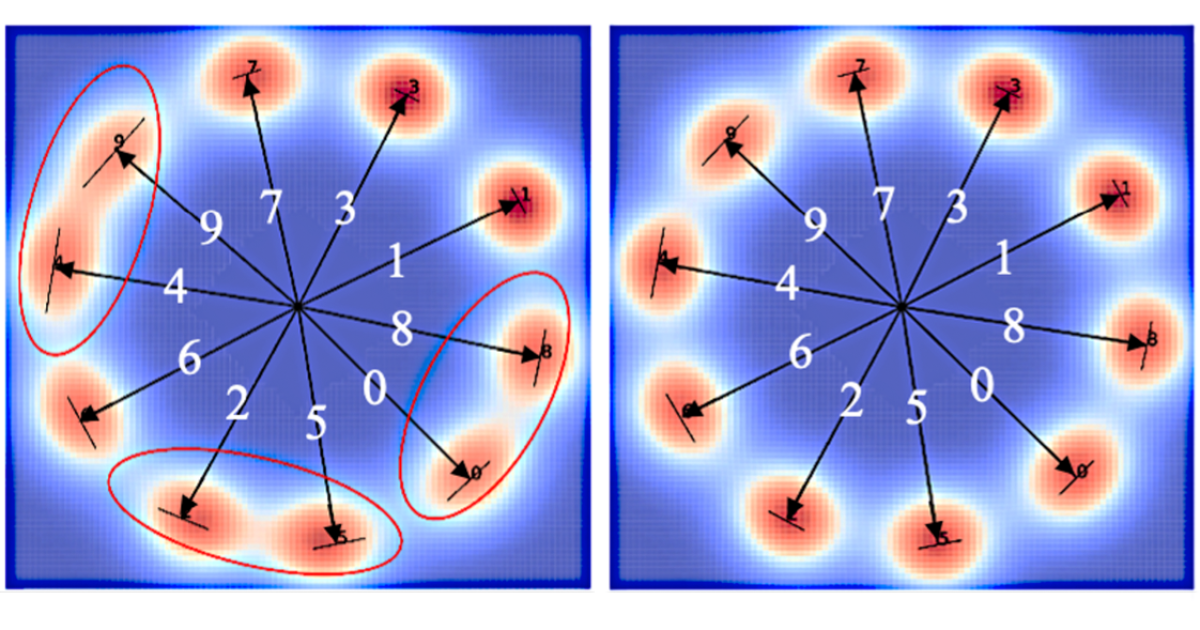
Upcaling image segmentation across data and tasks

The first draft of this blog post was generated by Amazon Nova ProBased on detailed instructions from Amazon Science editors and several examples of previous submissions. In a paper we present at the 2025 conference on computer vision and pattern recognition (CVPR), we introduce a new approach to image segmentation that scrosal different data and … Read more