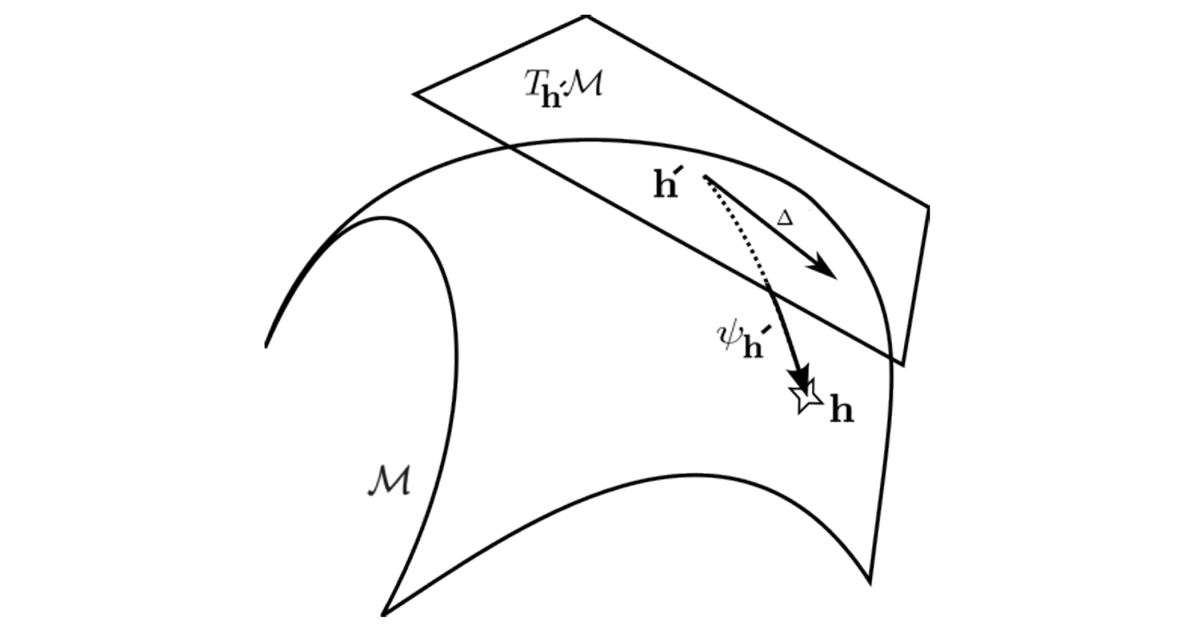
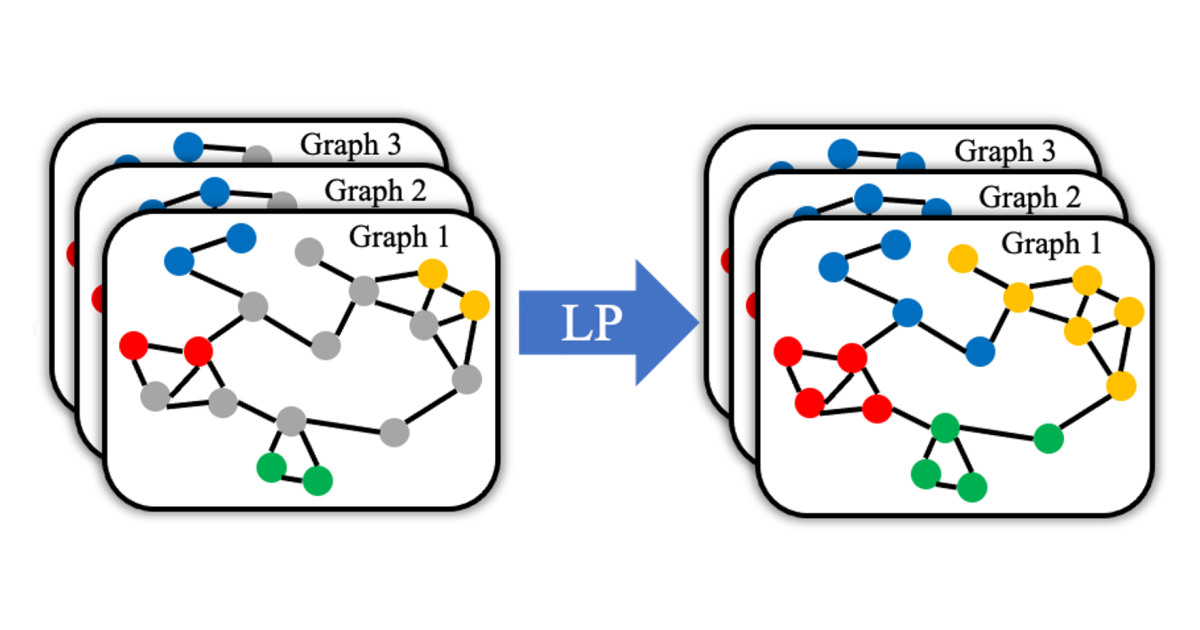
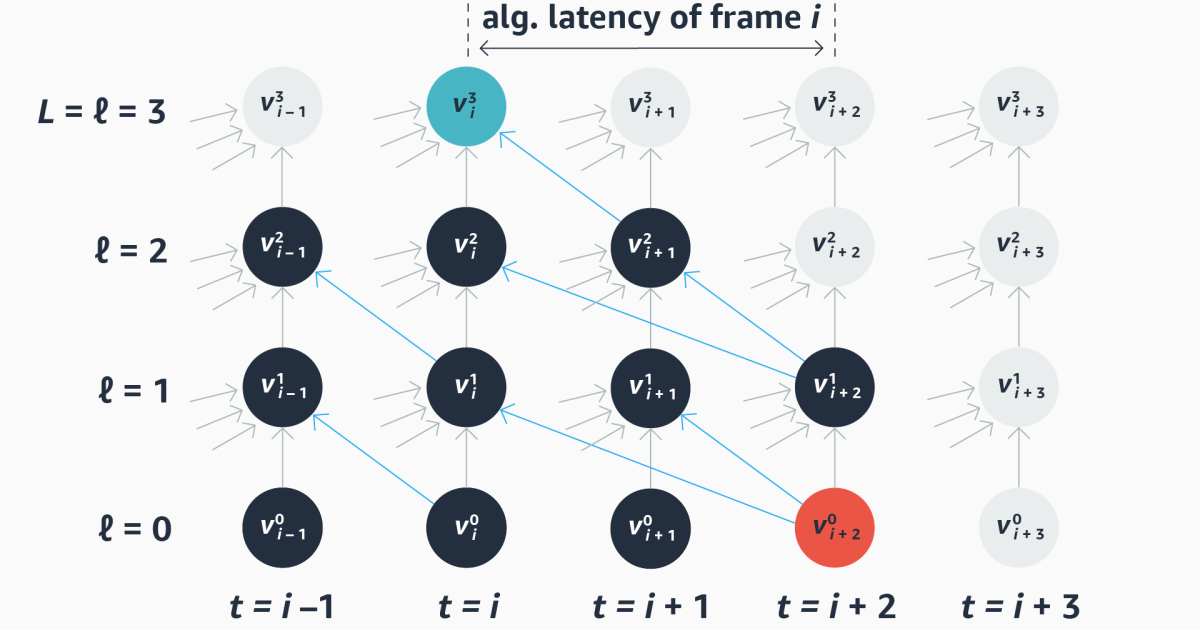
Howzon Chime SDK’s voice tone analysis works
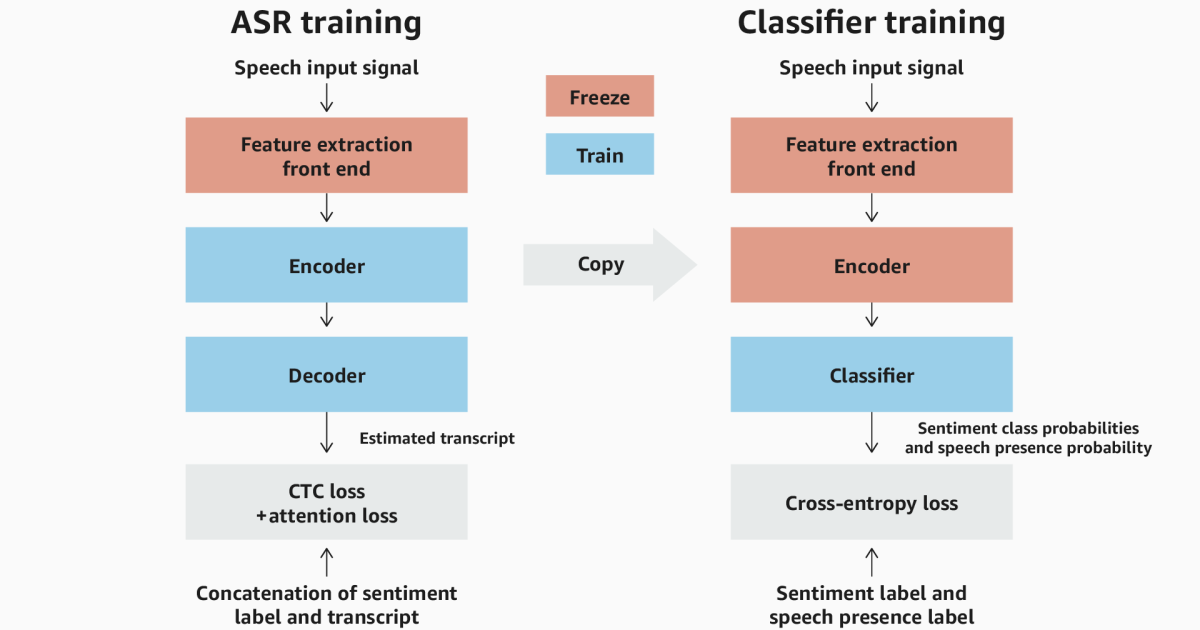
Human speech conveys the speech and feelings of the speaker through standing the words spoken and the way they are spoken. In speech-based computer systems such as voice assistants and in human-human interactions such as call-center sessions, it is important to understand speech density to improve customer experiences and results. Related content A person’s tone … Read more