
In the last five years, speech synthesis technology has moved to all-neural models that allow the separate elements of speech-proodi, accent, language and speaker identity (voice) to be controlled separately. It is the technology that allowed the Amazon-Text-to-Tale group to teach the feminine-sounding, English-language Alexa voice to speak in perfectly highlight us Spanish and the masculine-sounding American voice to speak to a British accent.
In both of these cases, however, we had two advantages: (1) Abuant annotated speech samples with target accent that the existing voice model could learn from, and (2) a set of rules for mapping graphs – sequences of characters – to it phonemes -The minimal devices with phonetic information and input to our text-to-speech models of the target accent.
In the event of the Irish-accented, female-sounding English Alexa voice launched last year, we had none of these advantages-nin-nin grapheme-to-phoneme rules and a data set that was a magnitude smaller than those of British and American Spanish. When we tried to use the same approach to accent transfer that had worked in the previous boxes, the results were poor.
So instead of taking an existing voice and teaching it a new accent, we took footage of the accented speech and changed their speaker ID. This gave us additional training data to our Irish-accent text-to-speech model In the target voiceWhich greatly improved accent quality.
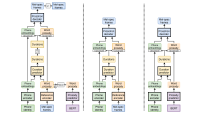
More Précisely, for Multispeaker, Multiccent Text -to -Speech (TTS) model, we first synthesized training data using a separate voice conversion (VC) model.
Input to the voice conversion model includes a speaker in -depth, which is a vector representation of the acoustic properties of the voice of a given speaker; A flour specistram, which is a snapshot of the frequency spectrum of the voice signal at short intervals; and the phonememen sequence associated with the spectrogram.

During exercise, the TTS model also receives a speaker in-depth, flour spectrograms and phonememen sequences, but at inference it does not receive the spectrograms. It is a multiccent, multispeaker model, so at training time it also receives an accent ide, a simple ordinary indicator of the input talk. At infernic time, the accent -id signal will still check the output of the talk.
Using a multiccent model is not important for our approval, but at Alexa AI we have empirically found that multiccent models tend to give more natural sounding synthetic speech than single-accent models.
The TTS model’s input also includes information extracted from the input number signal, about the duration of the individual input phonemes, giving the model better control of the accent rhyme. Again, at infernic time, there is no input number signal; Instead, the duration of the phonemes is predicted by a separate duration model trained in parallel with the TTS model.
Although we have no graphics-to-phoneme (G2P) rules for Irish-accented English speech, we need to generate input phonemes for our TTS model in some way, and we experienced with the G2P rules for both British English and American English. None of this is exactly accurate: For example, the vocal sound of the word “cannot” – and thus the associated phonem – different in Irish English than in any of the other two accent groups. But we were able to get credible results with both British English and American English G2P rules.
American English World a little better, and this is probably due to rhoticity: American English speaking, as Irish English speaking, says their R’s; British English speaking usually drops them.
To evaluate our method, we asked reviewers to compare Irish English speech synthesized by our method of recordings of four different Irish English speakers, one of it was our source speaker – the one who gave the speech that was the basis for accent, reviewers assessed the recordings of the source speaker as approx. 72.56% corresponding to other registrations of the same speaker; They assessed our synthesized speech (in another voice) 61.4% corresponding to items for the source speaker.
When reviewers We are asked to compare the accent of the source paint with them from the other three Irish English speakers, the score of the equality dropped to 53%; When the score of the equality was asked to do the same with our synthesized speech, 51%were. In other words, reviewers believed that our synthesized speech approximated the “average” Irish accent around as well as the source speaker. The fact that Agement is so low – for both real and synthetic speech – is a testimony to the diversity of accents in Irish English (Somits called the language a million accents).
To baseline the results, we also asked reviewers to compare speech that was generated through on approach to speech generated through the leading prior approach. In general, they found that our approach offered 50% improvement in accent equality over the previous approach.
Recognitions: We would like to recognize other Canelas to identify the opportunity and run the project and Dennis Stansbury, Seán Mac Aodha, Laura Teefy and Rikki Price for their support to make the experience authentic.