
For years, Amazon researchers have examined the topic of extremely multilable classification (XMC) or classification of input when the space for possible classification categories is large – says millions of labels. Along the way we have advanced modern art several times.
But the previous work was in the setting of a classic classification problem, where the model calculates a probability of each label in the room. In a new paper that my colleagues and I presented at the two -year meeting of the European Chapter in Association for Computational Linguistics (EACL), Intain Approach XMC as a generative problem, where for each input sequence of words, model generates are an output of labels. This allows us to utilize the power of large language models for the XMC task.
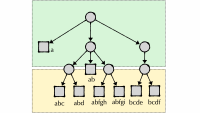
In this setting, as in the classic setting, it is difficult for most of the labels in the XMC label area to belong to a long tail with few representative studies in the training data. Previous work solved this problem by organizing the label area in a hierarchy: Input is first classified gross and successive improvements to the classification crossing the hierachic tree and arriving at a cluster of semantically related concepts. This helps the model learn general classification principles from Exameles that are related but have different labels, and it also reduces the likelihood of the model getting a label completely wrong.
In our paper we do something similar using a supplementary network to group labels for cluster and use cluster information to guide the generative model’s output. We experiment with two different ways to provide this guide during training. In one, we feed a bit vector indicating which clusters apply to a text input directly in the generative model. In the other, we fine -tune the model on a multitask goal: The model learns to predict both labels from clyn names and cluster names from texts.
In Tests, we both compared these approaches to advanced XMC classifiers and a generative model fine-tuned on the classification task without the benefit of label clusters. Across the line, the generative models with clusters surpassed for better than the traditional classifiers. In six out of eight experiment, at least one type of cluster-guided model matched on baseline-generative model’s performance across the entire data set. And in six experiments on long tail (rare) labels surpassed at least one cluster-guided model the generative baseline.
Architectures
We consider the task where a model receives a document – such as a Wikipedia post – as input and emits a set of labels that characterize its content. To fine -tune the generative model, we use data sets that contain sample texts and labels used for them by human annotators.
As a baseline -generative model, we use the T5 language model. Where Bert is a language model and the GPT-3 is only a decoder language model, the T5 is a Coder Discoder model, which means it uses two-way other than unidirectional coding: When it predicts labels, it has access to the input sequence as a white. This fits well with our setting, where the order of the labels is less important Thanir accuracy, and we want the labels that best characterize the entire document, not just the subsection of it.
To create our label clusters we used a lure generate embedders For the words of each document in the training set – that is, to map them to a represented space where proximity indicates semantic equality. The embedding of a given label is then average embedding of all the documents that contain it. Ounce labels are embedded we use k-Mans clusters to organize them in clusters.
In the first architecture we consider, as we call XLGen-BCL, the Grind-Truth label clusters for a given document represented as in a little matrix; All other clusters represent as zeros. During training, the matrix is transferred to the model as an additional input, but at the inferency the model only receives text.

In the other architecture, XLGEN-MCG, the clusters are awarded number. The model is trained on a multitask dimensions that at the same time learn to map cluster numbers for labels and texts for cluster numbers. At infernic time, the model receives only text. First, it assigns the text a set of cluster numbers, and then it maps the cluster number for labels.
Experience
We evaluated our two cluster -controlled generative models and four base lines using four datasets, and on each data set we assessed both overall performance and performance on rare (long tail) labels. When assessing the overall performance, we used F1 scores which factors in both false positives and false negatives, and we used two different methods for average per-label F1 scores. Macro average On average, the F1 scores for all labels. Micro average Summer all true and false positives and false negatives across all labels and calculates a global F1 score.
When assessing the benefit of long-tailed labels, we considered labels that only occurred once in the training data.
We also performed a set of experiment using positive and unmarked (PU) data. That is, for each training example we removed half of the group’s truth brands. Since a label removed from an example may still be shown in another example, it can still appear as an output label. The experiment thus evaluated how well the models are generalized across labels.
On PU data, the generative models dramatically exceeded the traditional classifiers, and the XLGEN-MCG model significantly exceeded the generative baseline.