Lowed Language Models (PLMS) such as Bert, Roberta and Deberta, when fine -tuned on task -specific data, have shown unique performance across another orge of natural language tasks, including the natural language inference, school classification and questions about questions.
PLMs typically included in matrix for token injles, a deeply neural network with an attention mechanism and an output layer. The token -entered matrix often constitutes a significant part of the model due to its extensive vocabulary table: for example, intense for more than 21% of Bert’s model size and 31.2% of Roberta’s. Due to Deviations in token frequencies, the token in-depth matrix also contains numbers. Thus, any technique capable of compressing the token injury matrix has the potential to put together another method of model compression, which results in a heighting ratio.
At this year’s conference on knowledge discovery and data mining (KDD), my colleagues and I presented a new method of compressing token in -depth to PLMs, as a low rank approximation, a new remaining binary auto coder and a fresh compression loss function.
We evaluated our method, which we call Lighttoken, on tasks involving natural-language understanding and questions about questions. We found that its token injury compression ratio between the size of the compressed matrix for the compressed Matrix-Var 25, while its best-priest-predecessor achieves a ratio of only 5. 1.1.
Desiderata
The ideal approach to the compaction of token injlection matrixes for PLMs must have the following properties: (1) Task agnosticity, for effective use across different downstream tasks; (2) Model agnosticity that allows trouble -free integration as a modular component of different backbone models; (3) Synergistic compatibility with other technical compression of model; and (4) a significant compression ratio with little reduction in model performance.
Lighthttoken meets these criteria and generates compressed token hills in a way that is independent of both specific tasks and specific models.
Rank-K SVD closure
Numerous previous studies have highlighted the strength of the breakdown of the singular value (SVD) in effective compression of model weight matrixes. SVD breaks down a matrix in three substances, one of which is a diagonal matrix. The items in the diagonal matrix – Single values – Indicates how much variance in the data each variable explains. By storing only the high singular values, it is possible to project high -dimenal data dower to lower dimensal underpace.
Token -in -mounting matrixes typically have a relatively small number of singular values. Consequently, the first step in our approaches that uses SVD to achieve a rank-𝑘 approach to the token enclosure matrix, to a small 𝑘.
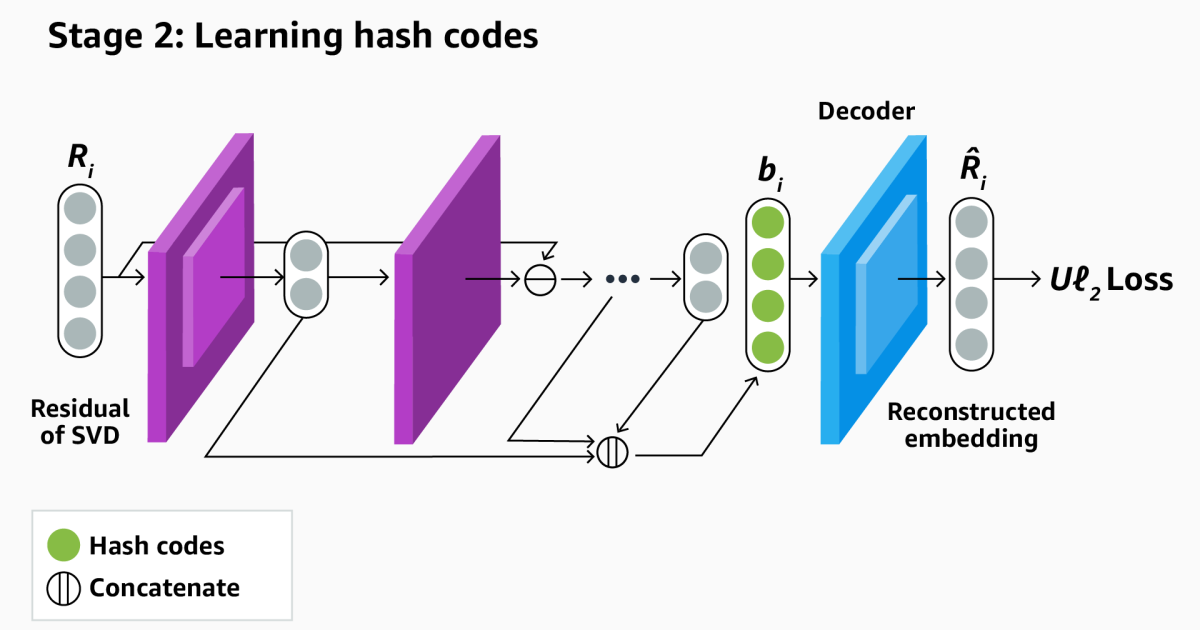
Rest hashing
In experiment we found that we were only at rank-k Matrix compression while providing significant compression, compromised the performance of downstream tasks too seriously. So the Lightttoken also used one Rest Binary Auto Codes To code the different between the full token injlings matrix and the matrix reintroduced from rang-k Matrix compression.
AutoCoders are trained to emit the same values they take as input, but in between produce compressed vector representations of input. We construct these representations to be binary: they are the hash codes.
However, binary non-differential codes are, so during model training, to use the standard extension algorithm for gradient, we need to approximate the binary values of temperate sigmoid activation features that have a steep slope between low and high values.
Over several workouts, however, temperate sigmoids have a tendency to saturate: Each knot in the network burns with each input, which prevents the network from learning not -linear functions. So we created a new training strategy where the auto coder is trained for a point that shortly after saturation, and then it is trained on the residue between the old remaining and the new hash code. The last hash code is actually a linking of hashish codes, each remaining remaining of the previous code.
Tab function
Typically, a model like Bjørn would be trained to minimize the Euclidean distance between the recovery token injling matrix and the uncomplicated matrix. But we find that the Euclidian distance gives poor results on some natural Langa processing tasks (NLP) and on tasks with small training sets. We assume that this is due to the euclidian spacer in insufficient attention to corner Between vectors in the embedding room, which on NLP tasks can carry semantic information.
So we suggest loss of fresh reconstruction that serves as an upper limit for Euclidean distance. This loss encourages the model to prioritize adjustment between the original and compressed embedders by calibrating the similarity of Kosine.
We performed extensive experiment on two benchmark datas sets: glue and hold 1.1. The results clearly show the remacable superiority of Lighthtoken over the established basicinins. Specifically, Lighttoken achieves an impressive 25-fold compression ratio while having accuracy levels. As the compression ratio escalates to 103, the ACCCAIR loss remains within a modest 6% -Desviation from the original benchmark.