Like the area of conversation AI generally, Amazon’s papers are dominated at this year’s meeting in Association for Computational Linguistics (ACL) of working with large language models (LLMS). The properties that make LLMS ‘output so extraordinary – such as linguistic flowering and semantic context – are also notorious difficult to quantify; As such, model evaluation has emerged as a specific focus area. But Amazon’s papers are exploring a wide range of LLM-related topics, from apps such as code synthesis and automatic speech recognition to problems with LLM training and implementation, such as continuous preceding mitigation and hallucination limitation. Papers accepted to the recently consecrated Course of ACL Is marked with stars.
Synthesis code
Fine tuning of language models for common rewrite and completion of code with potential errors
DIFINMIN WANG, JINMAN ZHAO, HENGZHI PEI, SAMSON TAN, SHENG ZHA
Continuous pre -determination
Effective continuous premium to build domain -specific large language models*
Yong XIe, Karan Aggarwal, Aitzaz Ahmad
Data quality
A shocking amount of the Internet is machine translated: Insight from Multi-Way Paullelism*
Brian Thompson, Mehak Dhaliwal, Peter Frisch, Tobias Domhan, Marcello Federico
Summary document
The force in summary source adjustments
Ornst, Ornst Shapira, Aviv Slobodkin, Sharon Adar, Mohit Bansal, Jacob Goldberger, Ran Levy, Ido Dagan
Mitigated hallucination
To learn to generate answers with quotes via Billetal Consistency Models
Rami Aly, Zhiqiang Tang, Samson Tan, George Karypis
Inteent classification
Can your model tell negage from an implicature? Disclosure of challenges with intent codes
Yuwei Zhang, Siffi Singh, Sailik Bedupa, Igor Shalyminov, Hwanjun Song, Hang Su, Saab Mansour
Irony recognition
Multipico: Multilingual Perspectivist Irony Corpus
Silvia Casola, Simona Frenda, Soda Marem Lo, Erhan Sezerer, Antonio Uva, Valerio Basile, Cristina Bosco, Alessandro Pedrani, Chiara Rubagotti, Viviana Patti, Davide Bernardi
Knowledge grounding
Graf Chain-Inf-Toughthought: Increasing Large Language Models By Resonating On Graphs
Bowen Jin, Chulin Xie, Jiawei Zhang, Kashob Kumar Roy, Yu Zhang, Zheng Li, Ruirui Li, Xianfeng Tang, Suhang Wang, Yu Meng, Jiawei He
Material: Memory -increased transformations immature scientific sources*
Dongkyu Lee, Chandana Satya Prakash, Jack GM Fitzgerald, Jens Lehmann
Wood-AF-Travel: A Zero-Shot Reasoning Sales Salvorithm for Reinforcing Language Models With Black-Box with Knowledge Graphs
Elan Markowitz, Anil Ramakrishna, Jwala Dhamala, Ninareh Mehrabi, Charith Peris, Rahul Gupta, Kai-Wei Chang, Aram Galstyan
LLM decoding
Bass: Batchet Attention Optimized Sampling Sampling*
Haifeng Qian, Sujan Gonugondla, Sungsoo Ha, Mingyue Shang, Sanjay Krishna Gouda, Ramesh Nallapati, Sudipta Bedpta, Anoo Deoras
Machine translation
Effects of incorrect spelled queries on translation and product search
Greg Hanneman, Natawut Monaikul, Taichi Nakatani
The fine tuning paradox: Increased translation quality without sacrificing LLM skills
David Stap, Eva Hasler, Bill Byrne, Christof Monz, KE Tran
Model editing
Propagation and pitfalls: Reasoning -based assessment of knowledge editing through counterfactual tasks
Wenyue Hua, Jiang Guo, Marvin Dong, Henghui Zhu, Patrick NG, Zhiguo Wang
Model evaluation
Bayesian Prompt Sets: Model Ucertain Estimate for Black-Box Large Language Models
Francesco Tonolini, Jordan Massiah, Nikolaos Aletras, Gabriella Kazai
Consider- The Human Evaluation Framework: Rethinking Human Evaluation for Generative Large Language Models
Aparna Elangavan, Ling Liu, Lei Xu, Sravan Bodapati, Dan Roth
Billing of Trust in LLMS: About Liveliness and Robustness of Current Estimators
Matéo Mahaut, Laura Aina, Paula Czarnowska, Momchil Hardalov, Thomas Müller, Lluís Marquez
Fine-tuned machine translation metrics fight in unseen domains
Vilém Zouhar, Shuoyang Ding, Anna Currey, Tatyana Badka, Jenyuan Wang, Brian Thompson
Measurement of questions answered difficult for recycling-augmented generation
Matteo Gabburo, Nicolaas Jedema, Siddhant Garg, Leonardo Ribeiro, Alessandro Moschitti
Robustness model
Extreme error calibration and the illusion of conflicting robustness
Vyas Raina, Samson Tan, Volkan Cevher, Aditya Rawal, Sheng Zha, George Karypis
Multimodal models
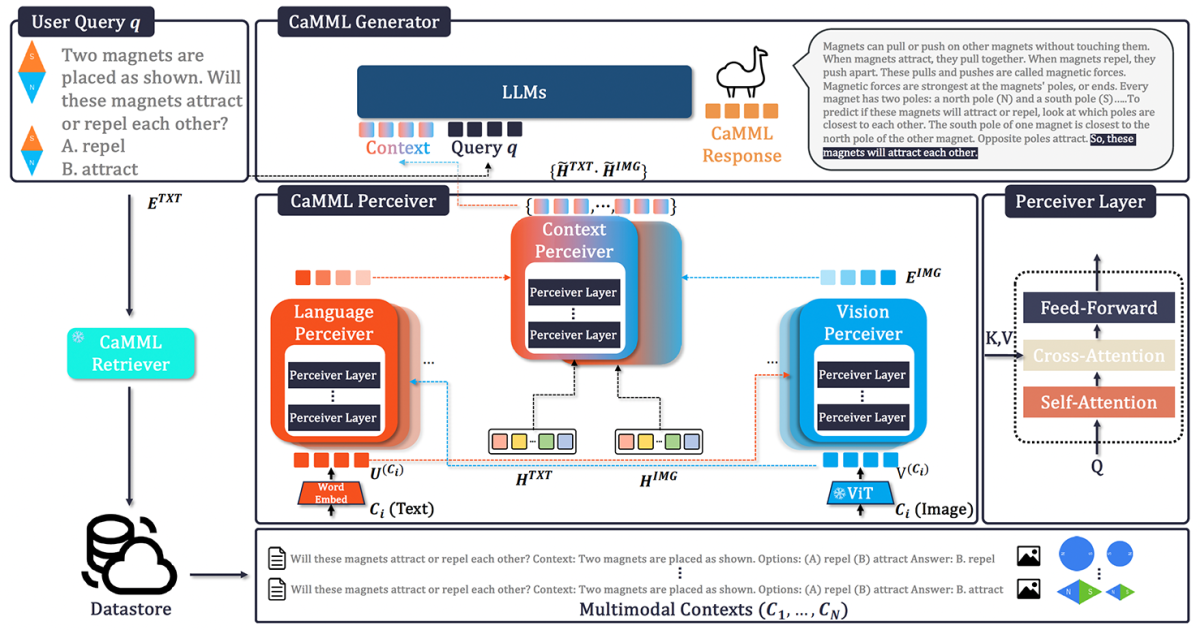
CAMML: Multimodal contextual teacher for large models
Yixin Chen, Shuai Zhang, Boran Han, Tong He, Bo Li
Multimodal retrieval to great language model -based speech recognition
Jari Kolehmainen, Aditya Gourav, Prashanth Gurunath Shivakumar, Yi Gu, Ankur Gandhe, Ariya Rastrow, Grant Strimel, Ivan Bulyko
Refinesum: Self-Affording Mllm to Generate a Multimodal Summary Data Set
Vaidehi patil, Leonardo Ribeiro, Mengwen Liu, Mohit Bansal, Markus Dreyer
Ordinal classification
Examination of Ordinality in Text Classification: A comparative study of explicit and technically implicit
Siva Rajesh Kasa, Aniker Goel, Sumgh Roychowdhury, Karan Gupta, Anish Bhanushali, Nikhil Pattisapu, Prasanna Srinivasa Murthy
Answering questions
In addition to bounds: a human -like approach to questions that answer over structured and unstructured information sources*
Jens Lehmann, Dhananjay Bhandiwad, Preetam Gattogi, Sahar Vahdati
Minprompt: Minimal graph-based quick data increase for a par-shot question answer
Xiusi Chen, Jyun-Yu Jiang, Wei-Cheng Chang, Cho-Jui Hsieh, Hsiang-Fu Yu, Wei Wang
Synthesis of conversations from unmarked documents using automatic response segmentation
Fanyou Wu, Weijie Xu, Chandan Reddy, Srinivasan Sengamedu, “SHS”
Reasoning
To evoke better multilingual structured reasoning from LLMS through code
Bryan Li, Tamer Alkhouli, Daniele Bonadiman, Nikolaos Pappas, Saab Mansour
II-MMR: Identification and improvement of Multimodal Multi-Hop Resonance in Visual Question Answer*
Jihyung Kil, Farideh Tavazoee, Dongyeop Kang, Joo-Kyung Kim
Recumend systems
Generative Explo-Exploit: Exercise-free optimization of generative recommendation systems using LLM optimizers
Besnik Fetahu, Zhiyu Chen, Davis Yoshida, Giuseppe Castellucci, Nikhita Vedula, Jason Choi, Shervin Malmasi
Against translation of objective product intoma customer language
Ram Yazdi, OREN KALINSKY, ALEXANDER LIBOV, DAFNA SHAHAF
AI Responsible
Taleguard: Examination of the contradictory robustness of multimodal large language models
Raghuveer Peri, Sai Muralidhar Jayanthi, Srikanth Ronanki, Anshu Bhatia, Karel Mundnich, Saket Dingliwal, Nilaksh Das, Zejiang Hou, Goerich Huybrechts, Srikanth Vishnubhotla, Daniel Garcia-Romero, Sun Hoff
Text ending
Token alignment via character matching to finish submarine*
Ben Athiwaratkun, Shiqi Wang, Mingyue Shang, Yuchen Tian, Zijian Wang, Sujan Gonugondla, Sanjay Krishna Gouda, Rob Kwiatkowski, Ramesh Nallapati, Bing Xiang