Forecasts for time series are important for decision -making across industries such as retail, energy, finances and health care. However, the development of accurate machine learning-based prognosis models has traditionally demanded significant data set-style and model adjustment.
In a paper we have just sent to Arxiv, we present Chronos, a family of prior time series models based on language model architectures. Like large language models or vision-language models, chronos is a Foundation ModelThere learns from large data sets how to produce general representations that are useful for a wide range of tasks.
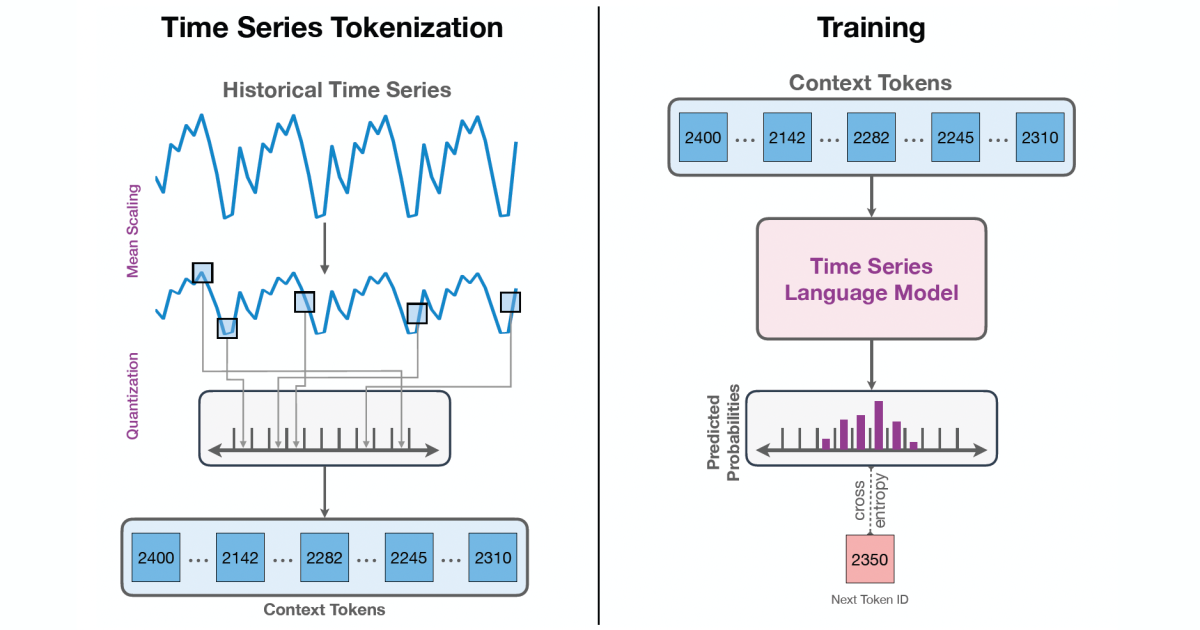
The most important insight behind Chronos is time series data as a language that should be models by transforming architectures out of shelf. To tokenize observations of time series in real value in a fixed vocabulary, we scale the time series with its absolute mean and then quantize the scaled time series to a fixed number of uniformly distributed trash cans.
In addition to these bin-tokens, we add two special tokens, pad and EOS, to denote padding/lack of values and end sequence, respective. We can shared standard language models such as T5 in such a “language for time series” using the constructive cross-bunny-loss function without changing the model architecture itself.
Despite its simplicity, Chronos is removable accurate. In an understanding evaluation involving 42 data sets, Chronos neglicant surpassed classic statistical methods as well as specialized dearing models on data that was held based on its training set. More important, we are pretty new data sets, Chronos’s zero-shot performance was comparable and occasionally superior than models trained directly on these data sets.
A nuclear strength of chronos is its ability to utilize different time series data from different domains to improve generalization. To improve the model’s robustness, we increase the public data used in advance with randomly mixed real samples (tsmix) and with a synthetically generated data set based on Gaussian processes (nuclear synt).

The impressive zero-shot capacities in Chronos position it as a viable “general purpose” forecasts that simplify implementation pipes. Instead of educating separate models for each tailor-made application, practitioners can use an off-the-shelf chronos model to immediately make accurate forecasts, reduce costs and make it easier to adopt advanced prognosis.
Despite Chronos’ strong empirical results, our investigation only scratches the surface of what we can achieve by adapting language modeling with time series. As the paper discusses, future research can explore more sophisticated time-series tokenization schemes, architectures tailored to serial data, and explicitly incorporating auxiliary functions or domain knowledge.
The use of prior models for time series is an exciting limit. By reformulating the forecasting task as a kind of language modeling, Chronos demonstrates a simpler path to general and accurate prediction. Furthermore, Chronos will be able to smoothly integrate future progress in the design of LLMs. We invite researchers and practitioners to engage in Chronos, now available open source, and join us in the development of the next generation of time series models.