Code generation-automatic translation of natural linguistic specialties into computer code-are one of the most promising uses of large language models (LLMs). But the more complex the programming task, the more likely LLM is to make mistakes.
Of race, the more complex the task, the more likely human Coders must also make mistakes. Therefore, troubleshooting is an important component of the software development pipeline. In a paper we presented at the 2024 conference on neural information processing systems (Neurips), we describe a new way of educating LLMs for Beter -debgers while improving the code generation.
Previous attempts to debug code with LLMs have primary used learning of few shots, where a feeder examples are delivered on successful debugs and LLM gives the rest. In our work, on the other hand, we use both monitored fine -tuning (SFT) and reinforcement learning (RL) to specialize an LLM for troubleshooting. Sales Failure Data is scarce, we utilize LLMs to create high quality synthetic training data.
We direct a number of experience where LLMs we gave an attempt to generate code in responsibility to a natural-langue prompt and a further attempt to troubleshoot this code. Becuse Our models had been fine -tuned with troubleshooting data, their initial generations were more successful than those, which an LLM depended solely on fast technique. But with both our models and the fast construction of baseline, troubleshooting always results in better performance code.
To evaluate model performance we used PAS@K METric where a model generates k Implementations of a natural language specification and it is an accident if at least one of these implementations passes a set of predetermined tests. In experiment with various code LLMS Inclusive Starcoder-15B, Codellama-7B and Codellama-13b-Our approach improved Pass@K-scores with up to 39% on standard benchmark data sets as MBPP.
Data synthesis
There are several widely used public data sets for generating exercise coding generation that include prompt with natural tip; Canonical implementations of the prompts in code; and Device TestSpecific sequences of input that may be to test the full functional rage of the generated code. But training data to Troubleshooting Models are relatively sparse.
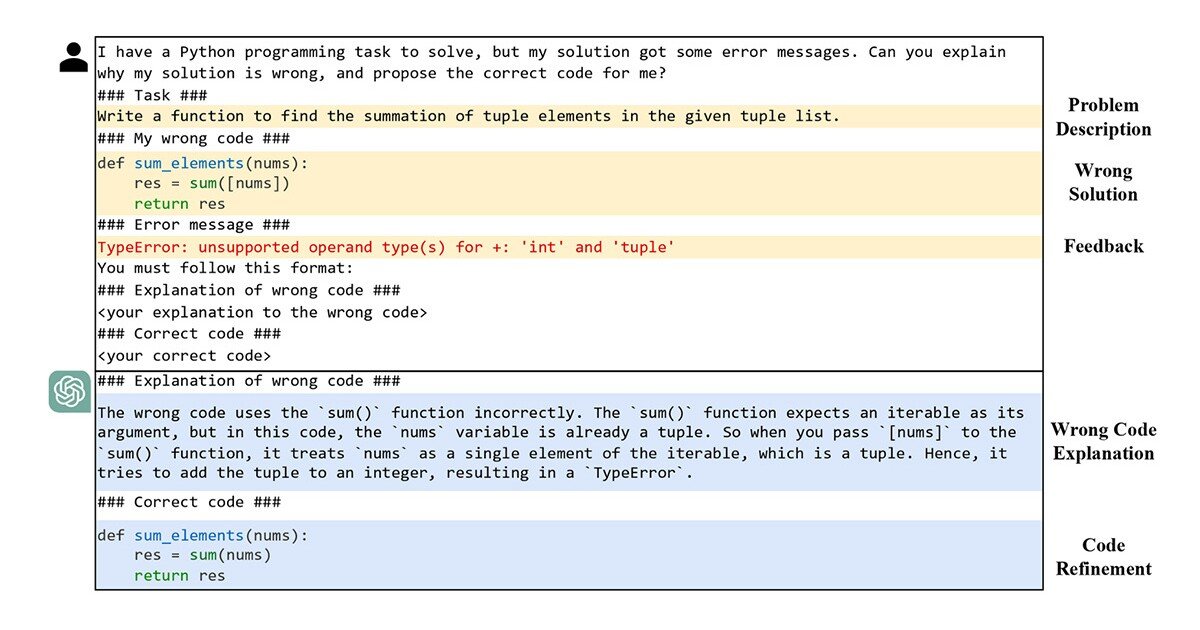
To create our debugging data set, we start legs with several of the existing code generation data sets. We repeatedly feed every natural-linguistic prompt in these data sets to a code generation model, resulting in a variety of generations-siger, 20-for the same prompt. Then we run the receiving unit tests of these generations and only keep those who fail The tests – that is, the buggy code.
Next, we feed the buggy code for an LLM along with the error messages it generated on the unit tests, and we ask LLM to explain where and errors occurred. Finlly, we take LLM’s diagnosis and feed it, the buggy code and the error messages back to LLM along with instructions to repair the error. This is a version of Chain-thought reasoning: Previous work has shown that asking an LLM to explain the action it intends to take before it takes this action often improves the benefit.
We then perform the unit tests on the revised code, this time only holds the revisions that pass All the tests. We now have a new dataset that consists of natural cleavage; Buggy implementations of these prompt; Diagnoses of the errors; Failed Code; and unit test.
Model updates
Armed with this data set we live yours to update our troubleshooting model using both SFT and RL. With both update methods, we experienced with training regimes, where we asked for chain-to-thoughts before we asked for the code’s revisions and those where we simply asked for audits.
With SFT we ask the model with the natural-Langae instructions, the buggy code and the error messages from the unit tests. Model outputs were evaluated according to their performance on the device tests.
With RL interacting the model iterative with the training data and trying to learn a Politics It will maximize a reward function. The classic RL learning algorithms require a continuous reward function to enable the exploration of optimization countrycape.
Device test feedback is binary, therefore discreet. To overcome this restriction, our RL rewarding feature includes, in addition to the success rate on the unit tests, also the revised code CODEBLEU score, which measures its distance from the code to the canonical example, providing a continuous reward signal.
Device tests are time and intensive resource to use, so training at CODEBLEU scores also opens the opportunity to train directly on the canonical examples, a much more calculation -efficient process. Our experience indicates that this approach improvve troubleshooting – though not as much as exercise in device testing as well.
Assessment
In our experience, we used three types of models: one was a vanilla llm that was completely for prominering; One was an LLM updated on our data set by using only SFT; And one was an LLM updated on our data set using both SFT and RL.
We implemented each type of model using three different LLM architectures, and for each model of model we measured three sets of output: an initial generation; A direct revision of the initial generation; And an audit that involves reasoning chain. Finlly we also examined two different generational paradigms: In one, a model was a chance to generate correct code; In the other it got 10 chances. This gave us a total of 24 different comparisons.
Across the line, our updated models surpassed the fast construction base lines. In all except one case, the version of our model passed up to date via Booth SFT and RL only the version updated via SFT. Generally, we demonstrate a scalable way of using feedback and canonical examples to better troubleshoot code models and improve their generational performance.