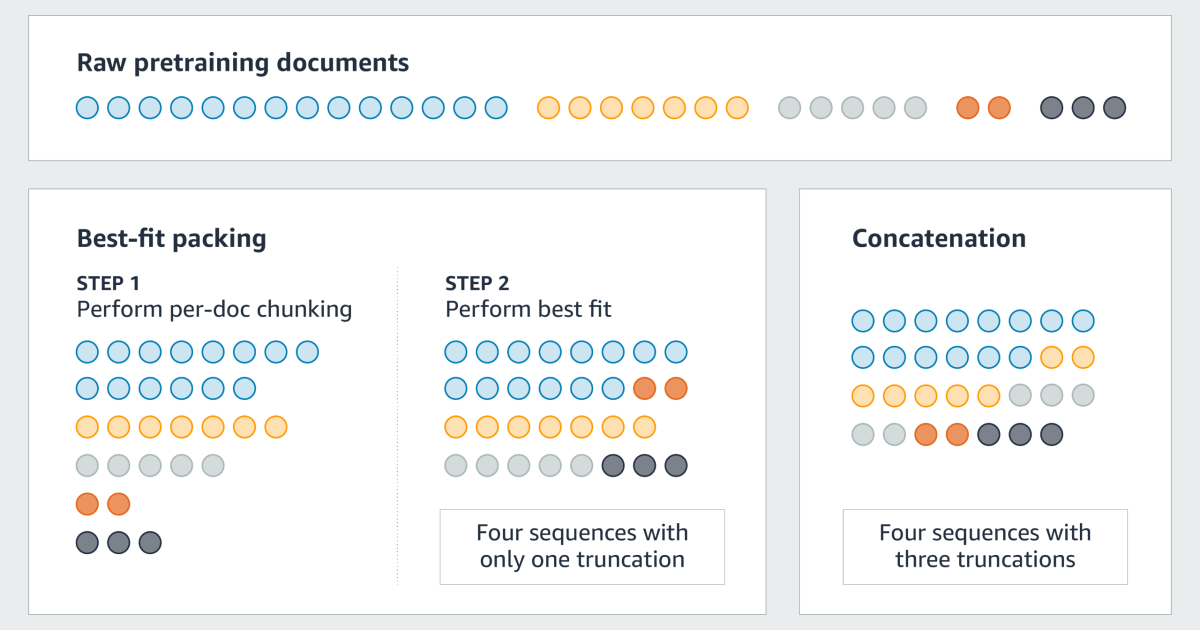
The documents used to train a large language model (LLM) are typically linked to forming a single “super document”, which is then divided into sequences, as the model’s context length. This improves exercise efficiency, but often results in unnecessary trunkings where individual documents are divided across successive sequences.
In paper we present at this year’s International Conference on Machine Learning (ICML 2024), entitled “Fewer truncations Improve Language Modeling”, we report an in-depth study of this common contiguous-chunking documents-prosessing method. We found that it seriously strangely has the model’s ability to understand contextual context and billing consistency. This not only affects the model’s performance on downstream tasks, but also disagrees the risk of hallucinations.
To add this result we offer Best care of packingAn innovative document insurance strategy that optimizes document combinations for elimate unnecessary text studies. In the experiment, we compared a model that was trained using the best care for one trained in the general way on six downnstream assignments: Reading comprehension, natural-langage inference, context after, summary, common and program synthesis. We found that the most suitable gasket monotonally improves the performance of a number of 22 sub -tasks, with as much as 15% (program synthesis) to 17% (context after). It is important that the best care of packing also reduces hallucination of closed domain effectively by up to 58.3%.
Consequences of truncation
In the analysis reported in our paper, we identified several problems.
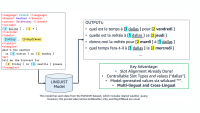
Undefined names: In programming languages such as Python, trunking can separate definitions of variables from their invitations, initial syntax errors and cause some variables to be undefined. As a consequence, the model can learn misleading patterns and possible hallucinate on downnstream tasks.
Unjorded content: Damage Data Integrity Availing. In the example below, a reference (the “earthquake Monday morning”) is separated, for example, from its antecedent, resulting in a faithful generation.
Lack of knowledge: Hinders Knowledge Collection hinders. In the example below, the model cannot learn the location of the ICML conference because the conference name and rent occur in different training sequences.
Best care of packing
To solve this problem, we propose to optimize the allocation of documents for training sequences to eliminate unnecessary trunkings while minimally increasing the number of links. This is a variation of the well-known bin-packing problem, which is NP-Hard in general, but we used a heuristic called The Best-Fit-Discraking (BFD) algorithm that tends to work well in practical. We thus call our method Best care of packing.
The normal implementation of BFD has quasi-linear time complexity, which is not effective enough for LLM pre-outgoing, which typically involves millions of documents. By tassing the advantage of the unique nature of prior data, however, we were able to optimize BFD so that they scale linearly with data size, ensuring that its utility to large -scale Pretraining data sets. We also show that in practical applications, best care packages generally generate the same number of training sequences as the traditional method, while the Nordic reduces data loss caused by trunc.
Are you curious to know how to achieve it? Let’s dive deeply!
Best Fitting Packing-An Example
After the standard bin-packing nomenclature, we call each exercise sequence a “bin” and each bin has a capacity equal to LLM’s context size. The goal is to assign a combination of which documents to each trash can to minimize the waste capacity.
First, we share any document that is larger than the LLM context in context length chunks, plus a reminder. Then we come out of the documents (and document fragments) from large to small. Finlly, we work our way down the sorted list, helping each document to the trash, the available space is as close to the document size as possible.

To maximize efficiency, we use these data structures to control the allocation of documents to trash cans: a binary tree and two tables. We can use this design because (1) The maximum trash can is the model’s context size so the tree is not too. Instead, we use the tables to map capacity to trash cans.
Consider a simple example where the context size (trash) is eight. The binary tree has eight leaves, corresponding to the eight options for available space in a given trash can. .
Each parent node on the tree has an associated number that indicates the size of wide Available bin castle among its descendants. The number associated with the parents’ right child is always greater than or equal to the number associated with the left child.
Originally, the value of the right node in each layer of ice has eight and all the other nodes have values of zero. This means that all the available bin slots have a capacity of eight.
Now consider the state when oven documents in size eight, six and oven are packed. The two trash cans containing documents of six have available slots in size two (8 – 6), and the trash can, which contains a document with size four, has an available slot of size four (8 – 4). These sizes represent with numbers two and four at leaves two and four of the tree. Several garbage cans remain empty, so leaf eight also has a value of eight.
Note that the value two at leaf two indicates only that at least one trash can in size two is available; It does not indicate how many such slots there are or where they can be found. This information is included in the tables.
Now consider a document of size three that we want to assign to a trash can. To find the best available bin slot simply go left at each knot of the tree, unless it goes to the left leading to a knot whose value is smaller than the document size, in which case go right.
The best fit for a size three document is slot in size four, and in the “Space-to-Bins” table we see that it is a bin-bin three with a slot of that size. So there we place the document.
Finlly, we update all three data structures to reflect the new location:
Results
To evaluate the effect of bin packing on downnstream tasks, we longed models of 7 billion and 13 billion parameters with context lengths of 2,000 and 8,000 on text and code using both best fit packing and coherence. We rested both sets of models on six downstream tasks. On average, several data sets, context lengths and measurements, best care packing offered better performance on all six tasks. The biggest winnings came in reading understanding (+4.7%), natural-linguistic inference (+9.3%), context after (+16.8%) and program synthesis (+15.0%).

We also found that packing the best suitable care helped prevent hallucination in dense domain, especially in program synthesis tasks, where the reduced “undefined name” error by up to 58.3%, indicating a more complete understanding of the program structure and logic .
In addition, models that are trained with best suited packing are better at following instructions such as adherence to longitudinal restrictions. And packing the best fit helped the model of acquiring “tail knowledge” It is sensitive truncation due to scarcity of training data. In fact, this result suggests why LLMs fight against knowledge of long tail.
While the experience performed in our Paper Primary, which is focused on LLM preliminary, the most suitable pack is widely useful for fine tuning. Determining the benefits it can offer during fine tuning is an exciting topic for future study.