Relationship databases (RDBS) store huge amants of structured data across several interconnected tables. This rich relational information has great potential for predictable machine learning. However, the progress of prediction models on RDBs is currently lagging behind progress in other domains such as computer vision or natural-langage treatment. An important reason is the lack of established, publicly available RDB -Benchmarks for model education and evaluation.
Existing predictable models for RDBs often go to use single -table data sets or graph data set DERV from pre -proseed relational data. However, these approaches do not fully capture the original multi-table structure and properties of RDBs, which potentially limits model performance.
To add this hole, Amazon’s Shanghai labeled developed 4DBinfer, a comprehensive Open Source-Benchmarking tool for graph center predictable modeling on RDBS.
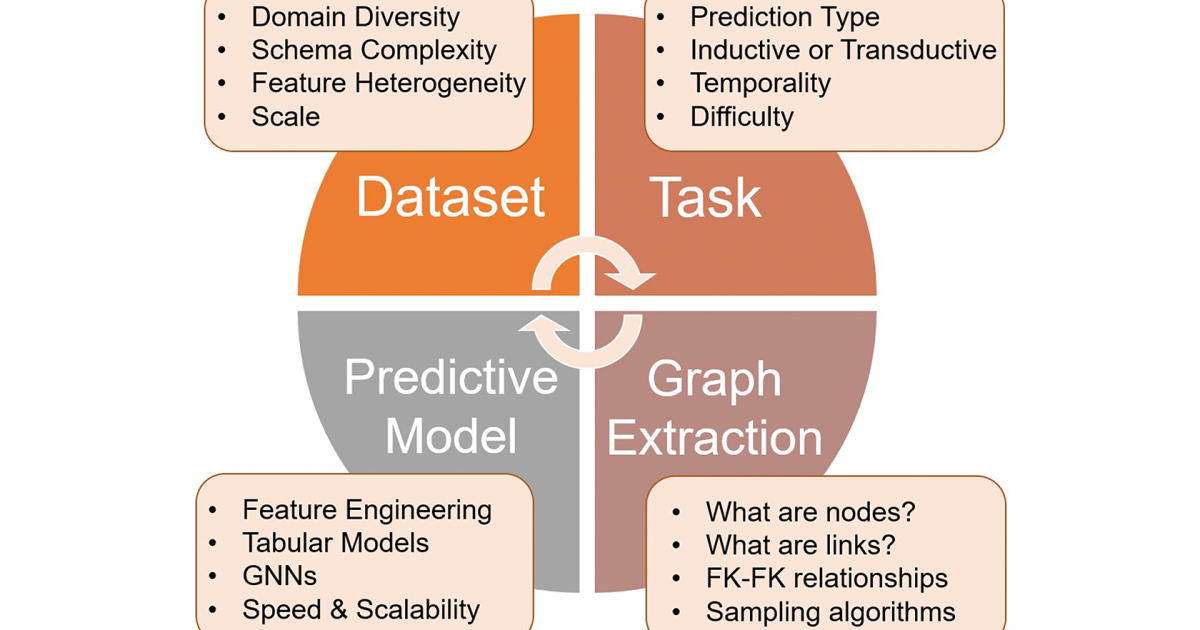
4DBinfer enables systematic comparison of different baseline models across four key dimensions: (1) RDB data set, (2) predictable tasks, (3) RDB-to-graph method extraction and (4) graph-based predictable architectures. This 4-D design facilitates a thorough exploration of the model design room for RDB Provision Analysis.
Let’s dive deeper into 4dbinfer’s core components:
RDB -Data sets and tasks: We curate for RDB-Benchmarks, which spans real application domains, including e-commerce, advertising and social networks. These data sets exhibit different properties with regard to scale (up to billions of rows), schedule complexity and temporal development. For each data set, we practically define to be predictable tasks, such as estimating lack of cell values.
RDB-to-graph extraction: 4dbinfer More supports for conversion of RDBs to Grap Representations while retaining rich tabular information. Tea Row2node The procedure treats each table row as a graphnode where foreign relationships plum that form the edges. Tea Row2n/e. Method selectively converts some rows to edges to capture more nuanced relational structures. 4dbinfer also introduced “dummy tabs” to enrich the graph connection.

Graph -based prediction models: We improve a rage of strong baseline architectures for graph-based learning that covers both Padigmm’s early and late function. These include Graph Neural Networks (GNNS), which learns knot holes based on relational message passing, as well as models that first extract tabular features from the graph using techniques such as Deep Feature Synthesis (DFS) before using classic learning radiants.
Comprehensive experiment using 4dbinfer provides several key insights:
- Using graph-based models to utilize the full Multi-Table RDB structure generally produces better results than using single-table or simple Table-Join models, highlighting the value of relational information.
- The choice of RDB-to-graph extraction strategy affects significant model performance, which emphasizes the importance of exploring this design space.
- Early merger graph models (eg GNNs) tend to surpass overall merger overall approaches, but the letter can still be competitive in some scenarios, especially during calculation restrictions.
- Model performance exhibits data set and task-specific variations that emphasize the need for different benchmarks to ensure reliable conclusions.
Through 4DBinfer, we love to accelerate research at GrafCenter-predictable modeling for RDBs by providing a total, fully open sourced frame. We believe that this work will enable society to develop new approaches that effectively exploit the power of relational data for predication tasks. Excitingly suggests our experiences that the most successful solutions can arise in the intersection of table -shaped and graphic machine learning paradigms – an area that is mature for further investigation.