One of the most important features of today’s generative models is their ability to take unstructured, partially unstructured or poorly structured input and convert them into structured ones that comply further.
Large Language Models (LLMS) can perform this task if you are quick with all schedule specialties and instructions on how to process input. In addition, most of today’s LLMs include a dedicated JSON mode or structured output mode that abstracts away some of this prominence from users.
Solm frame
Denoising and implementation of data registrations that follow specific schedules may involve predicting facts from schema descriptions or predicting schema descriptions from facts – a circular dependence. Solm breaks this addiction by regenerating the entire mail instead.
However, this approach has been limited. First, the cost of using LLMs is when they have to scale to databases with millions or billions of items or requests; Second, the potential complexity of the rapid technique is; And thirdly, the limited complexity of the schedules that the built-in JSON and structured output modes can support.
In two recent papers we published at the conference on empirical methods in natural language treatment (EMNLP) and on Arxiv, we presented a native approach to this problem in the form of a specialized lightweight -structured object language (sun). Ulim-Generel LLMS, Solm is trained to generate only objects in a specific schedule. SOLM’s contribution includes a special training method called Salf-Sub-Supervised Denoising and a special decoding method for use in infernic time called trust attentioned understuct Beam Search (CABS), which reduces hallucination risks.
In experiments, we found that Solm’s output accuracy matched or exceeded the advanced LLMs, while its cost -effectiveness was better. We also found that CABS decoding on the problem of product attributes generation approves an improved recall by 16.7% over conventional beam -search decoding when precision was set to 90%.
Applications
In our paper, we unite several seemingly non-related AI/ML problems during the formulation of structured output. For example, a challenge ishra has the structured object several Facetsor reduction of information space that depends on each other. A facet of the object can be a long descriptive text in natural language; Natorial facts can be short type -limited structured facts.
These types of multifaceted objects often occur in listing scenarios (products, houses, jobs, etc.), where the object contains a descriptive section and a section showing key attributes. Solm allows us to generate an object with these different types of facets, while throwing both relative consistency with the object and absolute consistency in terms of world knowledge.
The typical use of a structured output model involves feeding it a blurb of unstructure data and letting them generate the corresponding structured object. In our paper we also offer Solm as what we call a self -generation machine. In this case, we easily feed the model an object already structured according to the form and we let the model regenerate that end to end.
Here, the task is not long to structure input, but to clean, normalize, correct and/or end it and do it self -consistency. Of race, input may include any combination of an already structured post and additional unstructure content, or it may include a record that is structured in accordance with another schedule. Solm is agnostic in terms of input and will always generate a pure record deal for the target schedule.
The self -generation machine can solve multiplemer at once: completion of missing facts, correction of incorrect facts, normalization of informalized facts, completion of failure to description and correction of inaccurate information in descriptions. All of these tasks are interduependent and introduce addiction loops when treated independently (for example, you have to unpack facts from descriptions or write descriptions based on facts?). Self -generation solves for these dependencies in the most natural way.
Innovations
To train the SOLM model, we used self-monitored denoising. The idea is to use any sample of objects from an existing database, introduce artificial noise in these objects and train the model to restore their original form. The model thus learns to improve the quality of any object we feed into it. By making the noise more aggressive – for example, by removing the structure of the object or randomly mixed tokens – we learn not only to improve the quality of an existing object that also aims to function on complete unstructure input.
Cabs -Methodology
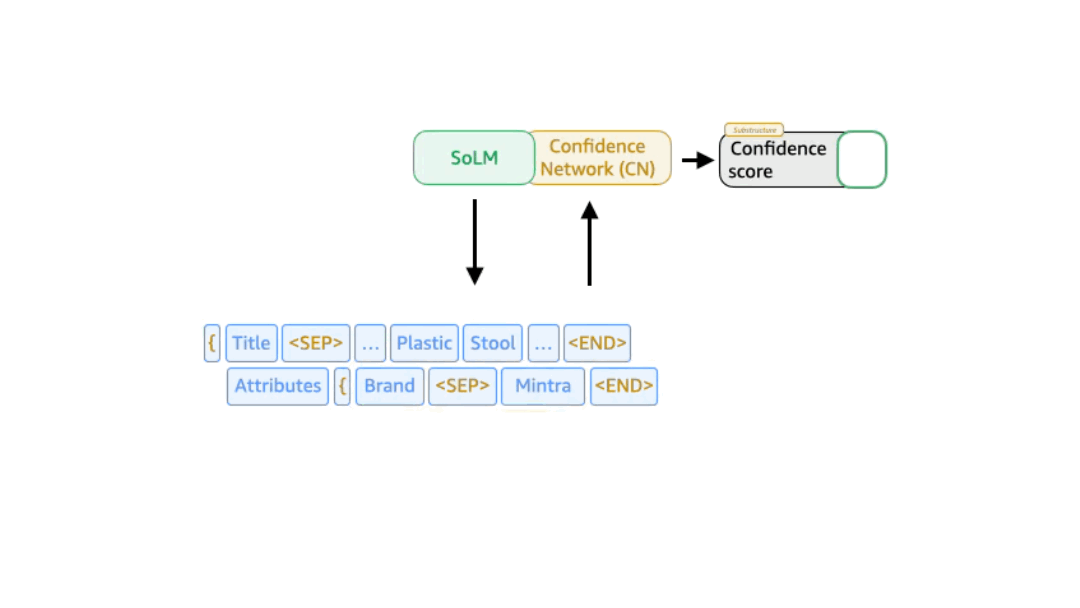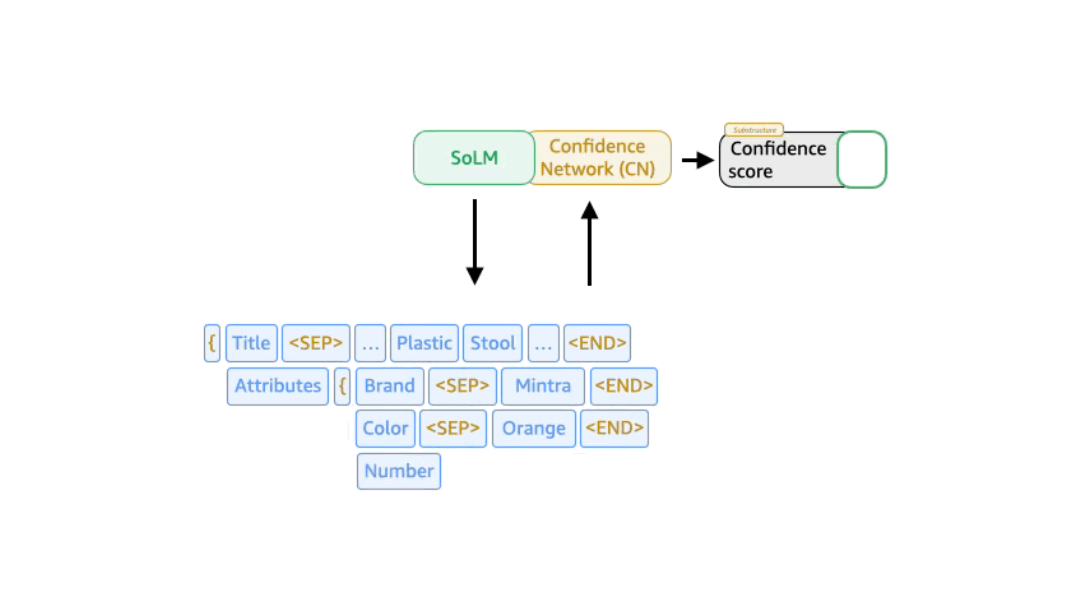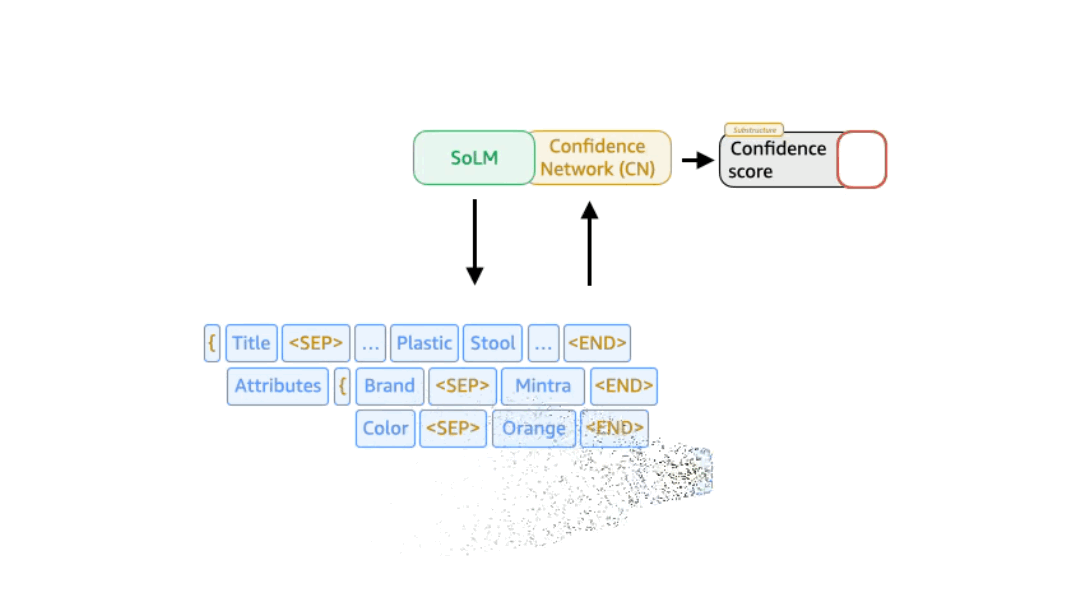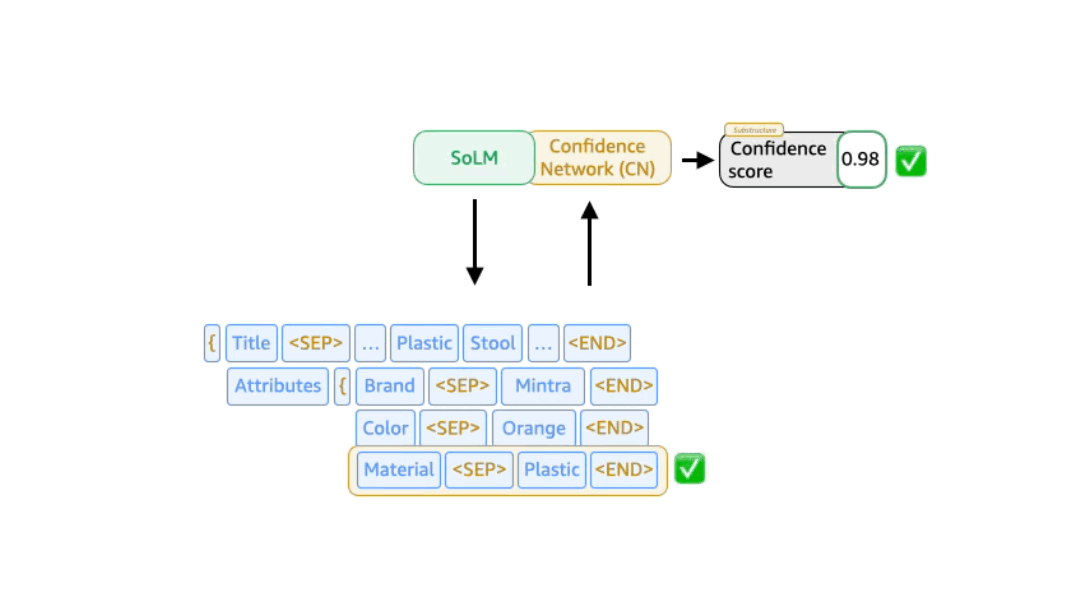
Confidence -conscious support Beam Search (CABS) Applied Beam Search at the level of the description couple and uses a separately trained network to predict each couple’s probability.
Although LLMs are trained simply to generate the most likely next token in a series of token, at infernic time, they typically use users Decoding strategies To select output. One of the most popular is Beam Search Decoding, where the model considers several candidate sequences in parallel, which ultimately chooses the sequence that has the highest cumulative probability. . Sequence of tokens over a specified number of turns.) The number of sequences that the model is considering at ounce, called width of the beam.
SOLMS OUTPUT consists of a number of key value peaks, where the key is a certain data type from Schedule case a specific products. We also use special tokens (“
In the trustworthy sub-structure-beam search, the key valuable is rather than the token nuclear component in the beam search. The probability of the key value diparet can be derived from LLM’s confidence in its output. But we also experienced with a separately trained confidence result model that takes as input the intermediate representation produced by one of LLM’s inner layers. In practice, this approach is better than relying directly on the model’s trust results.
In our papers we show that a SOLM model with seven billion parameters or surpasses various fast engineering techniques on very large basic models, across measurements, such as the completeness of the facts, the correctness of the facts and the quality and invoicing of the descriptive enthusiastic. In the case of enclosing, we further increase the correctness of the facts by removing facts that we hallucinated during decoding.