One of the ways Amazon Web Services (AWS) helps customers stay secure in their cloud is with the AWS Security Hub, which aggregates, organizes, and prioritizes security alerts from AWS services and third-party tools. These alerts are based on security controls – rules that help ensure the services are configured securely and in accordance with best practices.
Traditionally, the development and implementation of Thécurity controls has been a complex, time-consuming and labor-intensive process. As cloud environments have grown more sophisticated, the demand for effective and scalable security solutions has only intensified.
In a paper we presented at the workshop on Genai and Rag Systems for Enterprise at this year’s International Conference on Information and Knowledge Management (CIKM), we describe a new model that leverages AI capabilities to automate the creation of security controls that enables faster, more efficient and highly accurate generation of the rules that help users protect their cloud infrastructures.
The current challenge
Developing security controls for AWS involves analyzing service documentation, writing detailed offerings (often in Gherkin format), and ultimately developing the code to ensure secure configurations. On average, it can take 24 days to produce a single security check. The complexity of this process will grow as AWS continues to expand its portfolio of services, with each service including numerous resources that must be protected, and manually twisting and reviewing controls can cause delays in deployment.
Enter generative AI
The new model uses large language models (LLMs) to automatically generate Gherkin specifications. This reduces the time taken from days to mother in second place. When you’re up to speed with model service documentation and descriptions of the security requirements, LLMs can issue accurate control specs ready for deployment.
For example, LLMs can generate Gherkin specialties—known as Gherkins—for basic security requirements, such as stagnation of data at rest or logging. This process helps ensure that jobs using AWS services like Amazon Sagemaker Automl are properly configured to meet security standards without engineers having to dive into documentation each time.
Domain-specific AI for security
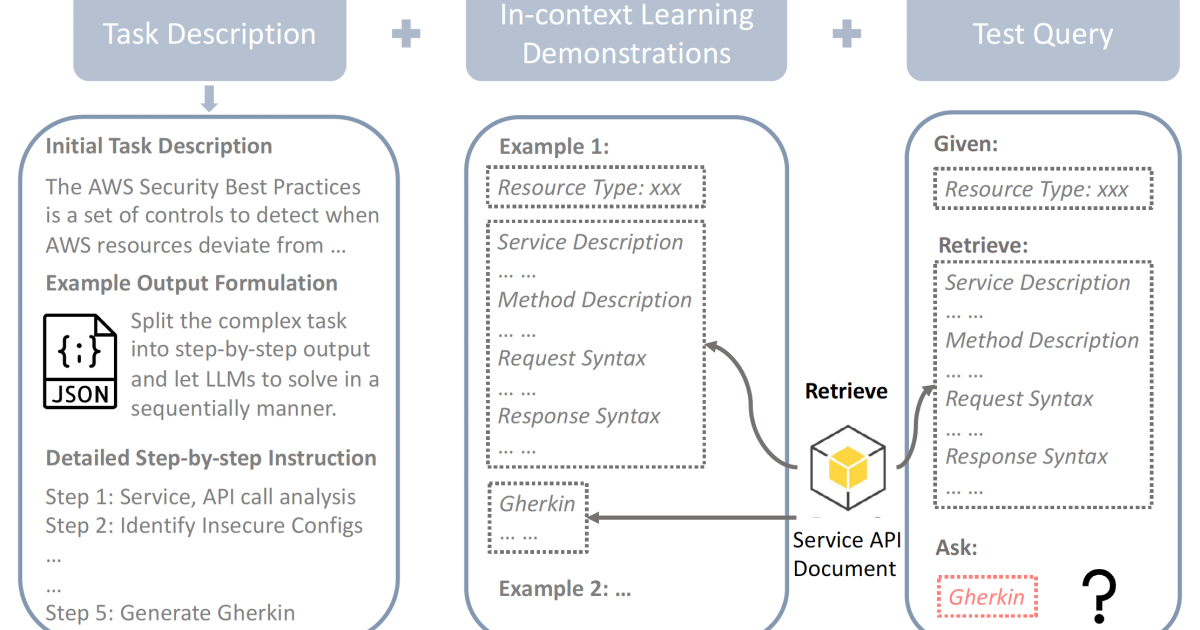
Rapid engineering is the process of designing precise input requests to guide the construction of a language model toward the desired outputs. The goal of fast technique is to ensure that the model understands the context and purpose of the task, leading to more accurate and receptive responses.
In the new model, we combined a few fast construction techniques to improve the performance of LLM and increase the transparency of its output. First, we used chain reasoning to break down the complex task of generating gherkins into sequences of simpler steps. In each step, the LLM was instructed to create an intermediate result that was used as input to the next step.
We also used retrieval-augmented generation (RAG) to allow LLM to retrieve reporting information from external sources. In our case, the source was BOTO3 API specials, and the information was the configuration of services and resources, ExpressD in BOTO3 syntax, which was also added to the prompt.
The last technique we used was learning in context, where we add positive examples of Gherkins development from security engineers to the prompt. This has the effect of pushing LLM in the right direction, forcing it to mimic the positive examples and generate similar gherkins for the input query.
By combining these techniques, the new model is able to provide highly accurate and domain-specific security checks, which shorts significantly speed up the development process and improve overall security efficiency. In future work, we will further refine the system, potentially using agent-based architectures to handle even more complex control generation scenarios.
Recognitions: Felix Candelario