Whether collected through employee surveys, product feedback channels, voice-to-customer mechanisms, or other unstructured text sources, qualitative data offers invaluable insights that can complement and contextualize quantitative business intelligence. However, the manual effort required to analyze large volumes of open-ended responses has limited access to these insights.
Topic modeling approaches such as latent Dirichlet allocation (LDA), which groups documents based on word co-occurrence, can help uncover thematic structures in large text corpora. However, LDA and other standard topic modeling techniques often struggle to fully capture the contextual nuances and ambiguities inherent in natural language.
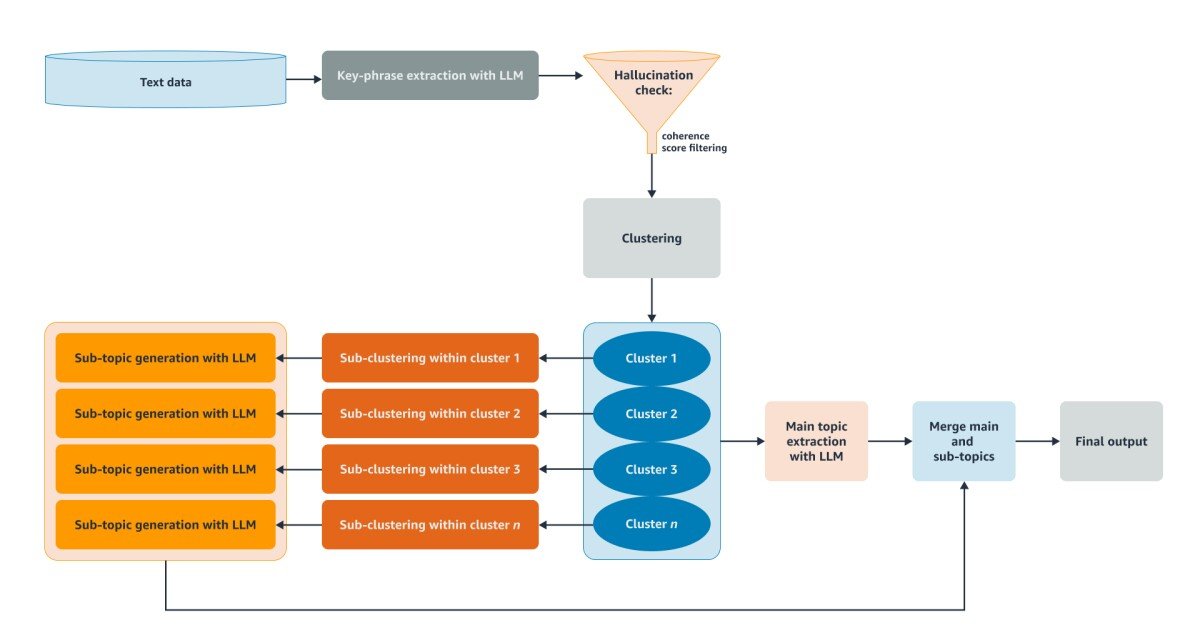
In a recent paper co-authored with Alex Gil, Anshul Mittal, and Rutu Mulkar, we introduce the Qualitative Insights Tool (QualIT), a new approach that integrates pretrained large language models (LLMs) with traditional clustering techniques. By leveraging LLM’s deep understanding and powerful language generation capabilities, QualIT is able to enrich the topic modeling process and generate more nuanced and interpretable topic representations from free-text data.
We evaluated QualIT on the dataset of 20 newsgroups, a widely used benchmark for topic modeling research. Compared to standard LDA and the advanced BERTopic approach, QualIT showed significant improvements in both topic coherence (70% vs. 65% and 57% for benchmarks) and topic diversity (95.5% vs. 85% and 72%).
Hierarchical clustering
QualIT does not simply rely on the LLM to generate topics and themes. It uses a unique two-stage clustering approach to uncover both high-level topic insights and more detailed subtopics. First, the model groups key phrases extracted by LLM into primary clusters that represent the overarching themes present in the corpus. It then applies a secondary round of clustering within each primary cluster to identify more specific subtopics.
The key steps in the QualIT approach are
- Key phrase extraction: LLM analyzes each document and identifies key phrases that capture the most salient themes and topics. This is a decisive advantage over alternative methods that characterize each document by a single topic. By extracting several key phrases per document, QualIT is able to handle the reality that a single piece of text can encompass a number of interrelated themes and perspectives.
- Hallucination control: To ensure the reliability of the extracted key phrases, QualIT calculates a consistency score for each one. This score assesses how well the key phrase matches the actual text and serves as a metric for consistency and relevance. Key phrases that fall below a certain coherence threshold are flagged for potential “hallucination” and removed from analysis, helping to maintain the quality and credibility of the topic modeling output.
- Clusters: The hierarchical structure of the two-phase clustering method provides a comprehensive and interpretable view of the thematic landscape, allowing researchers and decision makers to navigate from broad, overarching topics down to the more nuanced and detailed aspects of the data. Importantly, QualIT uses the key phrases as a basis for clustering rather than directly clustering the full documents. This reduces noise and the influence of irrelevant data, allowing the algorithm to focus on the thematic essence of the text.
In addition to comparing QualIT with previous topic modeling methods, we also asked human reviewers to validate its output. The reviewers were able to more consistently categorize the items generated by QualIT into the known ground truth categories; for example, when at least three out of four evaluators agreed on the topic classification, QualIT achieved a 50% overlap with the ground truth compared to only 25% for LDA and BERTopic. Interested readers can learn more about the technical implementation in both the QualIT paper and an earlier paper on unifying methodological paradigms in qualitative research.
Applications
Qualitative text does not only include feedback on surveys or from focus groups; it also includes product interaction data. For example, a system similar to QualIT could analyze the questions posed to an AI chatbot to understand which topics are most interesting to users. If the interaction data is paired with customer feedback data, such as thumbs-up/thumbs-down ratings, the system can help explain which topics the chatbot didn’t do well on.
Looking ahead, further enhancements to QualIT’s language modeling capabilities (such as support for languages beyond English, especially low-resource ones) and topic clustering algorithms promise to unlock even more powerful qualitative analysis capabilities. As organizations continue to recognize the value of qualitative data, tools that can effectively and efficiently emerge with meaningful insights will become essential.