E-commerce sites often recommend product related to customer question telephone boxes for someone who shops after a phone, for example. Information about product conditions is often representation of direct edges graphs, which means that the relationship represents of the edges (can) flow in Onely One Direction: It makes sense to recommend a case to someone who acts after a phone, for example someone who acts after a case needs a telephone recommendation.
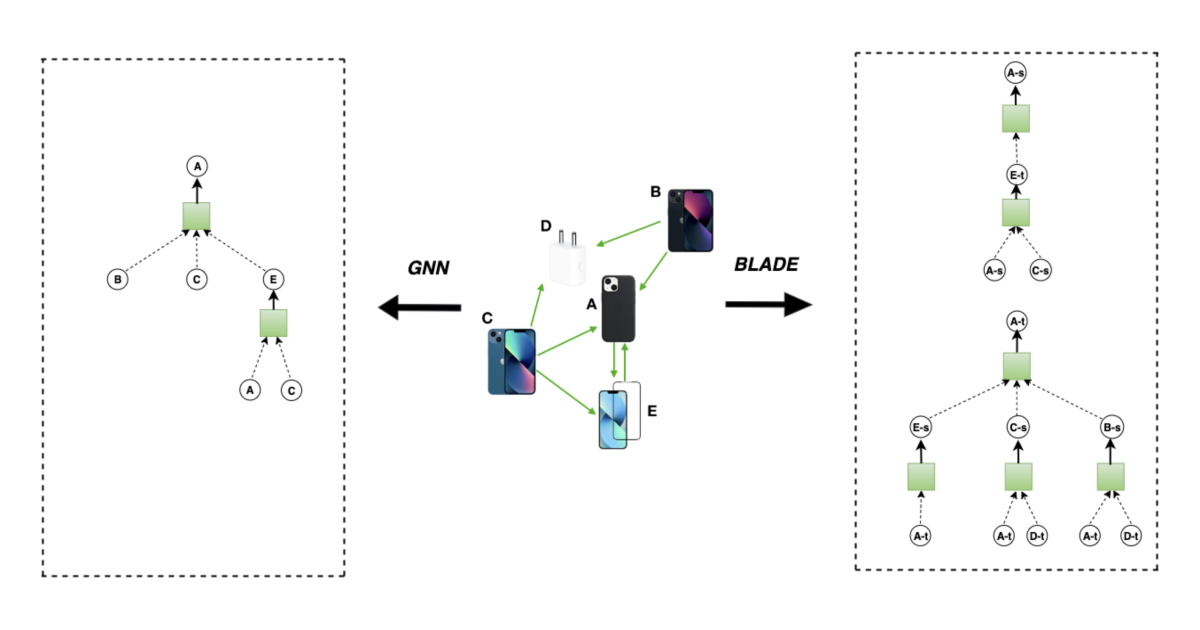
In a paper we presented last year at the European Conference on Machine Learning (ECML), we showed that graph neural networks can capture the direction of productness graphs using double deposits (vector representations) for each graphnode: A embedding represent the node that recommends other as target recommendation.
At this year’s ACM Conference on Web Search and Datamining (WSDM), we expanded the work of a new approach to impeed the nodes with direct graphs. Specifically, we tailor the embedding procedure to degree of the graphnode or how many connections it has to other nodes. This allows us to utilize the centrality of highly connected nodes as we span further afield to collect information about sparsely connected nodes.
In experiment, we compared the performance of our new model with them from this advanced predecessors on six different public data sets with three different numbers of recommendations per day. Inquiry (5, 10 and 20). Our model surpassed the others everywhere; Its edge over the second best execution ranged from 4% to 230%, measured by hit rate and average mutual rank.
Graph Neural Networks
Graf Neural Networks (GNNS) are neural networks that take graphs such as input and output hills for each graphnode that catches not only the knot but also about its relationship with other nodes. These embedders can be used for a variety of tasks, such as link prediction, anomaly detection or in our case, related-production recommendation.
GNN – in -joints are iterative: First, the network each node each node on the basis of its associated information – here, product information; Then it gene blines each knot based on both its own first embledding and those from the nodes connected to it. These processes can be repeated indefinitely and expand the neighborhood of the embedded knot to two hops, three hops – up to the size of the overall graph.
For graphs with many closely connected (high degree) nodes, it may be impressed to factor all a node’s neighbors in its embedding. In such cases, GNN will typically try the neighbors at each iteration of the embedding procedure.
In the typical implementation of a GNN, the size of each nodes neighborhood – the number of hops included in its embedding – is fixed. This number is often one or two. Sampling in node is also uniform: Each of a given node neighbors has an equal likelihood of factoring in the nod’s embedding.
This approach has restrictions. For a high degree of the node, a one- or two-hop in-depth can be sufficient: The Immonde neighborhood contains enough information to characterize the node. But for a low degree of hub, it may be necessary to follow a long chain of connections to collect enough information to produce a useful embedded.
Similarly, if the nodule that is embedded is connected to both a high degree and a low-degree knot, sampling the high-degree node will generally be more productive as its embedding contains more information about the neighborhood. Thus, uniform sampling misses an opportunity to enrich a node’s embedding.
Our approaches that we call leaves, for Partic locally adaptive direction awareBoth address these restrictions. It begins with the framework we presented earlier, which produce source and target holes for each knot.
However, the scope of its embedders varies depending on the degree of the inbound edges of the nodule that is embedded. In the paper, we show how to calculate the size of the neighborhood using a power law distribution that factors in the I-degree and minimum to the degree of all nodes in the graph. We also show how to estimate the power law coefficient by considering to a degree of all nodes in the graph.
We also provide a mechanism for weighting the likelihood of sampling a nodes’ neighbors during the embedding process by taking into account the degrees of these nodes, both in -depth and outgoing.
In addition to testing the six public data sets, we also tested it on two large internal data sets. There were the improvements that our model offers, equally dramatic, ranging from 40% to 214% compared to the other good performance. You can find more details in our paper.