Human speech conveys the speech and feelings of the speaker through standing the words spoken and the way they are spoken. In speech-based computer systems such as voice assistants and in human-human interactions such as call-center sessions, it is important to understand speech density to improve customer experiences and results.
To this end, the Amazon Chime Software Development Kit (SDK) -Team recently released a voice -tone analysis model, which Uste’s Machine Learning to estimate seedrings from a voice signal. We adopted a deep-neural network (DNN) architecture that extracts and jointly analyzes both lexical/linguistic information and acoustic/tonal information. The inference runs in real time on short signal segments and returns a set of probabilities as to express expresses positive, neutral or negative sensation.
DNN architecture and two-stage training
Previous approaches to voice-based sentence and emotional analysis typically consisted of two steps: Estimization of a predetermined set of signal features, such as pitch and spectral-energy swings, and classification of feeling based on these features. Such methods may be effective in classification of relatively short emotional utterances, but their performance deteriorates for natural conversation signals.
In a natural conversation, lexical features play an important role in conveying emotion or emotion. As an alternative to acoustic functional methods, some emotional analysis methods focus solely on lexical features by analyzing a transcription of the speech.
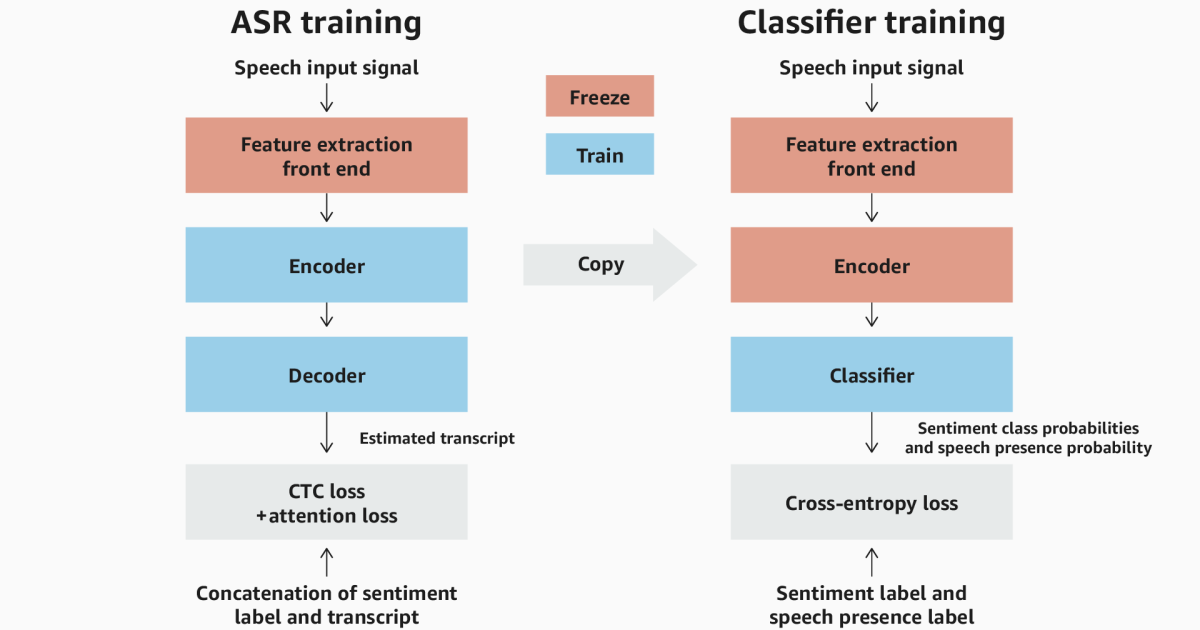
Amazon’s voice tone analysis takes a hybrid approach. To ensure that our model incorporates acoustic functions as well as linguistic information, we begin with an automatic-speaking (ASR) model with a coding decoder architecture. We train the model to recognize both emotion and speech, and then we freeze its codes to use the front end of a sense of classification model.
The ASR branch and the classification of our model are both fed by a deep-learning front end that is prior with the help of self-overview to extract meaningful speech signal functions, rather than the predetermined acoustic functions used in prior voting-based approaches.
The Enkoder of the ASR branch corresponds to what is often referred to as an acoustic model that maps acoustic signal functions to abstract representations of word piles or phonemes. The decoder corresponds to a language model that collects these chunks for meaningful words.

In the ASR training, the front end is held and the ASR codes and decode -parameters are trained using a transcription with a preply feeling -for example “Positive I am so happy.” The loss function scores the model on how well it maps input functions to both the sensation mark and the transcript. The coder thus learns both tonal information and lexical information.
After the ASR training is completed, the classification is built using the mocked front end and the trained ASR codes. The code output is connected to a slight classification and the parameters of the frontend and the ASR codes are both frozen. Then using the sense of the brand voice inputs, we train the classification to emit the likelihood of positive, neutral and negative emotions. It is also trained to detect speech presence – ie. where input contains any speech at all.
The purpose of educating another branch for classification is to focus on these outputs from the ASR codes, which are important to estimate feeling and speaking presence and to emphasize the output that corresponds to the actual transcription of the input sewing.
Uterine dataset for training
Previous models for voice -based sentence and emotional analysis have generally been trained small -scale data sets with relatively shorts, but this is not effective in analyzing natural conversations. In our work, we instead use a combination of multiple data sets.
Our multitask-learning approach requires the training data sets to include transcripts and sense of labels. Available data sets of not always have both. For data sets that have prints but do not feel labels, we use Amazon understand to estimate text -based emotions from the transcriptions. For data sets that have feelings of brands but not transcripts, we use Amazon Transcript to estimate transcripts. For spoken data sets that have neither prints nor feel labels, we use Amazon TransCribe and understand how to estimate booth.
With this approach we can perform ASR training with multiple data sets. We also use data increase to ensure robustness with regard to entry signal conditions. For Augment Stack consists of spectral increases, changes in speech speed (95%, 100%, 105%), reverberation and additive noise (0DB to 15dB SNR). In addition to training with different data sets, we also test with different data and evaluate the model performance of different data grille sections to ensure justice across demographic groups.
In our tests we found that our hybrid model exceeded prior methods that were exclusively on EITH text or acoustic data.
Bias reduction to feel labels
Since the frequency of the emotional labels in the training data sets is not uniform, we used several bias technical reduction. For the ASR training internship, we try the data so that the distribution of emotional labels is uniform. In the classification training, we emphasize the loss function component in each feeling of feeling, so that it is inversely proportional to the frequency of the corresponding emotion mark.

In general, there is a trend in data sets so that neutral emotions are more widespread than positive or negative. Our sampling and loss function weighting techniques can reduce bias in the detection rats for the neutral, positive and negative, improved model accuracy.
Real-time inference
The inference model for our voice tone analysis consists of the prior front end, the trained ASR cod codes and the trained classification. It is worth noting that our classification is much less calculated expensive than an ASR duck codes, which means that our voting tone analysis system can run inference to low costs that require a complete text transcript.
Our voice tone analysis model has been implemented as a voice analysis feature in Amazon Chime SDK Call Analytics, and in its production configuration it runs on five second voting segments level 2.5 seconds to give real-time probability estimates of speech presence and feeling. The model is configured to use the short -term feeling of the probability of calculating emotional estimates over the last 30 seconds of active speech as well as over the full duration of the speech signal.