Automatic-Tale Recognition Models (ASR), which converts speech to text in voice agents, typically have two phases. The first phase involves a deeply neural network that maps acoustic information representing an utterance to several hypotheses about the spoken words. The second internship is a language model that evaluates (rescores) the plausibility of these hypothetized word sequences.
The first phase – the acoustic model – is optimized for average performance on a large set of speakers; Therefore, it tends to work poorly on speech varieties that are underrespressed in the training kit, such as statements found in regional accents. Standard resort methods cannot correct for this type Majoritarian bias In the first step speech recognition machine.
All are sanded #ICASSP2023Please come by poster presentation, “cross-user ADR saving with graph-based label formation”.
Time: June 9, 8: 15-9: 45 am Greece time
Rental: Poster range 4 – Garden (Speech Recognition: Modeling and Context) pic.twitter.com/r9vqcqodnn– Srinath Tankasala (@rinath_tank) June 6, 2023
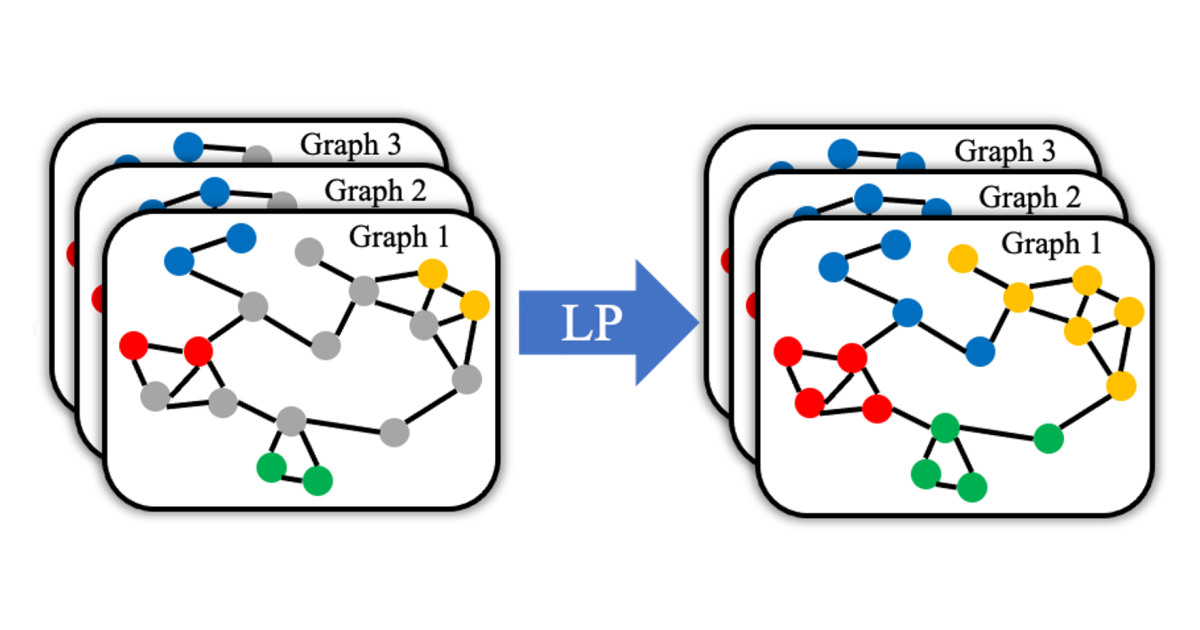
At this year’s International Conference on Acoustic, Speech and Signal Treatment (ICASSP), we presented a new approach to reporting speech recognition hypotheses that can help recover after mistakes that have been under-represented in or otherwise misunderstood to the training data.
Our approval builds a graph from speech samples with different speakers, but similar hypotheses, and it creates edges between utterances that sound similar. Then it increases the likelihood of the hypotheses shared by adjacent nodes in the graph, which means that similar-dust utterings cause similar hypotheses to be increased. This has the effect that the statements of words that are unlikely isolated can support each other if they are made up of several utterances.
In the experiment, we tested the cross-users’ rescoring method on the database with regional accentic English. The speech recognition had mainly been trained in North American English and therefore showed high error rates for speakers from England, Scotland, Ireland, India, etc. Our Appach lowered the word error rate acts as the board with an average of 44%.
The algorithm requires comparison of the dishes of the dishes of utterances, and it is extremely useful head in semi-over-over-over-learning. In this setting one, typically large, learn ASR model brands training data to another, usal more calculating effective, Student Model. By attaching more comfortable labels to speech tests with under -represented speech patterns, we can diversify the data used in training and Ultimataly helps overcoma the majoritarian bias.
This year, ICASSP organizers generalized the concept of the best paper price by recognizing the 3% of papers accepted at the conference. We have honored that our paper was Included in this group.
Graph construction
We are considering the case where initial transcription hypotheses are produced by a fully trained, recursive-neural-network-transducer (RNN-T) ASR model. An RNN-T-Model is a Coder-Decoder model, which means it has a cod module that maps input into a representing space and a decooder module using the mappings known as embedders – To generate ASR hypotheses.
To seek out these hypotheses, we adapt the technique of graph -based label formation to spread labels from the brand to unmarked examples. In our case, the graph nodes take, recordings, and the labels are the ASR hypotheses from the first recognition pass.
The first step in our graph construction method is to select the data for recording in the graph. We divide the data into groups of utterances with significant overlap into their ASR hypotheses, and we construct a separate graph for each such group. A single graph, for example, can largely consist of similarly formulated queries about the weather.
When we know which utterances to include in the graph, we measure the distance between their embedders. We experienced with several different spacers, but struck us down on wooden tremetrically based on dynamic time spread (DTW). DTW was originally designed to measure distances between time series, but we treat each value in the embedding vector which essentially a separate time step. A DTW-based spacer metrically works well to this application empirically it correlates well with between the utterance transformers, measured by editing distance.
On the basis of the distance measurements, we calculate edges between graph nodes. We experienced with weighting the edges according to the DTW distance between nodes, but again, empirically, we found that binary edges the world best. From the data we learn at a distance threshold; All nodes whose distances from each other fall below this threshold are connected to the edges, and those whose distances exchanged that the threshold remains unexplored.
Propagation mark
When setting the semi-monitored learning, the graphs included some annotated data whose transcripts are very accurate and large amounts of unannounced data. We use standard graph-based label formation algorithms to distribute “goodness results” to different ASR hypotheses across the graph. Essentially, these algorithms are designed to minimize radical interruptions in label values between connected (ie similar) graphics.
The idea is that even if the ASR model has awarded a low confidence result for the correct transcription of an utterance that contains non -standard outlets, the excrement of this devised parts edges with utterings where the correct transcription will receive high trust score. The correct transcription rotates propagated across the region of the graph, and the odds will increase the utterance with non -standard pronunciation transcript correctly.