In most of the last 10 years, Machine Learning (ML) was the heaviness of the concept embedding: An ML model would learn how to convert input data to vectors (embedders) so that geometric conditions within the vector room had semantic consequences. For example, words whose embeddies were close to each other in the representative space could have similar meanings.
The concept of embedding an obvious collection of information collection: An inquiry would be embedded in the reproof room, and the model ALD chooses the answer whose embedding was closest to it. This world of multimodal information retrieval as text and images (or other modalities) could be embedded in the same space.
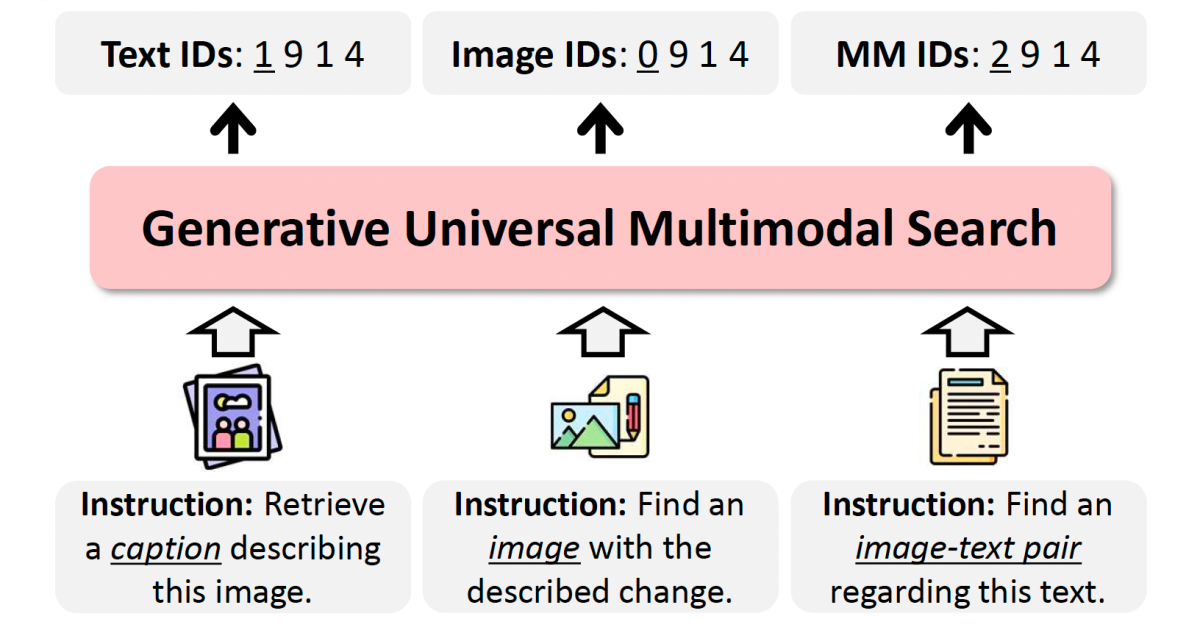
Recently, however, generative AI has come to dominate ML research, and at the 2025 Computer Vision conference and pattern recognition (CVPR) we presented a paper that updates ML-based information collection to the generative AI era. Our model, called genius (for generative universal multimodal search), is a multimodal model whose input and output can be combination of images, texts or caption peers.
Instead of comparing a query vector with any possible vector-a time-consuming task if the image catalog or text corpus is large enough-our model takes an inquiry as input and generates single ID code as output. This approach has been tried before, but genius is dramatically improved on previous generation -based information methods. In tests on two different data sets using three different Metrics retrieval accuracy when one, five or ten candidate responsible for retrieved genius is improved on the best advancing prior generative collection model by 22% to 36%.
When we are our conventional embedding -based methods of redirecting the top generated responsible candidates, we still improvise further, by 31% to 56%, which narrows the gap between generation -based methods and embedded methods significantly.
Paradigm shift
Information collection (IR) is the process of finding reporting information from a large database. With traditional embedding -based retrieval, queries and database elements are both mapped into a high -dimensional space, and the similarity is measured by means of measurements such as Kosine’s equality. While effective, these methods are facing scalability problems as the database grows, due to the increase cost of index building, maintenance and nearest neighbor search.
Generative retrieval has emerged as a promising alternative. Instead of embedding items generating generative models direct identifiers (IDS) of target data based on an inquiry. This approach enables the retrieval of constant time, prolonged database size. However, existing generative methods are often task -specific and fall short in performance compared to embedded methods, and they struggle with multimodal data.
Geni
Contrary to prior approaches limited to single modality tasks or specific benchmarks, genius generalizes across the retrieval of texts, images and caption peers, high speed maintenance and competition accuracy. Its benefits over previous generation -based models are based on two key innovations:
Semantic quantity: During training, the model’s target output -ids are generated through Remaining amount. Each ID is actually a sequence of codes, the first of which defines the data cheese modality image, text or caption pair. The successive codes define the region of the data element in the representative space with greater specificity: items that share the first code are in the same general area; Elements that share the first two codes are clumsy more close to this area; Elements that share the first three codes are clumsy closer still, and so on. The model tries to learn to reproduce the sequence of codes from the input codes.
Inquiry increase: This is approaching results in a model that can generate Accarate ID codes for well -known types of objects and texts, but it can iron to generalize to new data types. To add this limitation we use Inquiry increase. For a representative sampling of inquiry-IID mates, we generate new queries by interpolating between the initial inquiry and target ID in the representative space. In this way, the model learns that a number of queries can map the same goal, which helps it generalize.
Results
In experiments using M-Beir-Benchmark, Genius surpasses the best generative retrieval method with 28.6 points in recall@5 on the Coco Data Set for Text-to-Billing. With embedded re-ranking, genius often achieves results close to those that are embedded base lines on M-beir-Benchmark while retaining the effector benefits of generative gathering.
Genius achieves advanced performance among generative methods and narrows the performance gap between generative and embedding-based methods. Its efficiency advantage becomes more significant as the data set grows, which maintains high recovery speed without the expensive index structure typical of embedding -based methods. Thus, it represents a significant step forward in generative multimodal retrieval.